


こんにちは、プロダクトAI開発の宮後(miya10kei)です。最近はMakuakeで変わったガジェットを探すのにハマっています🛠️
昨年、ニーリーで社内AIチャットボットのPoC開発をし、今年の4月から全社で本格的な利用を開始しました。現在は知識領域毎に特化した4つのチャットボットを運用しています。
| チャットボット | 説明 |
|---|---|
| AI Park Direct | Park Directのドメイン知識を回答してくれるチャットボット |
| AI Park Direct for Business | Park Direct for Businessのドメイン知識を回答してくれるチャットボット |
| AI 労務 | 労務関連の社内規定に関して回答してくれるチャットボット |
| AI Analytics | BIツールのクエリー検索/解説、NL2SQLなどを回答してくれるチャットボット |
今回は、最近新たに社内公開し評判の良かったデータ活用チャットボットであるAI Analyticsについて紹介します!
ニーリーでは現在BIツールとしてRedashを使用しており、さまざまなデータソース(本番DB、Zendeskチケット、Google Analytics)に対してクエリー実行できるようになっています。
しかし、データを閲覧するためには当然SQLを書く必要があります。また、本番DBのデータはテーブル構造も複雑になっているため、エンジニア以外の方が欲しいデータを自力で取得することは難しい状況にありました。データを取得したい場合は、社内のAnalyticsチームにクエリー作成を依頼することで対応しています。
そんな中で、自然言語で既存のクエリーを検索できたり、新規クエリーを作成できれば自力でのデータ取得が一定実現できるのでは?という話になりAI Analyticsを作り始めました。
AI Analyticsの主要な用途として次の3つがあります。
1. Redashクエリーの検索
現在、Redashには約2,300件のクエリーが蓄積されています。これだけの数になると、欲しい情報を取得するクエリーを探し出すのは容易ではありません。タイトルやタグによる整理は行っているためある程度の検索は可能ですが、自然言語による検索を実現できれば利便性は格段に向上します。
Q. ○○別に△△を集計する既存クエリーってある? A. https://example.com/queries/1234 です
2. Redashクエリーの解説
クエリーの中には数百行を超えるものもあり、中身を知らない人が見たときにどのような条件で取得しているかを把握することは難しいです。RedashのURLと一緒に分からない点や分析指標を質問し、回答を得れるようになれば情報の把握が容易になります。
Q. https://example.com/queries/1234 の条件を教えて? A. 条件は○○です。 ※ https://example.com/queries/1234 はBIツールのURLです。
Q. 契約可能台数ってどういう定義? A. 契約可能台数は○○です。
3. SQLの作成*
テーブル構造が複雑なため、構造に詳しくない人がSQLを書くのは骨の折れる作業です。欲しい情報を自然言語で指示することで、既存のクエリーを参考にSQLを作成してくれるようになれば情報へのアクセスが容易になります。
Q. ○○別に△△を集計するクエリーを作成して? A. SELECT * FROM ...
続いて、技術的な仕組みについて紹介します。
構成はとてもシンプルでS3バケットに必要な情報を保存し、Amazon Bedrockのナレッジベースの機能を利用してナレッジ化しています。フレームワークにはLangChainを利用しており、エージェントからナレッジベースのS3バケットを検索し、回答を生成するようにしています。
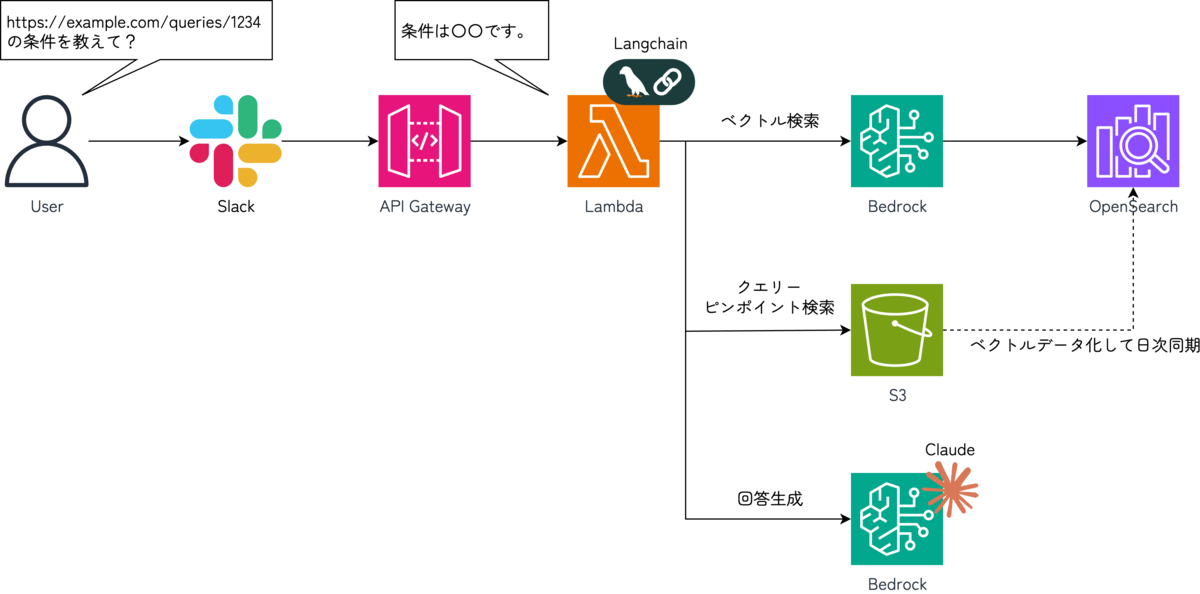
それではいくつかポイントを絞って詳細を紹介します。
S3バケットのデータ
S3バケットには既存のRedashクエリーとテーブル定義情報としてdbtのモデル定義を保存しています。
Redashクエリー
1クエリー、1Markdownファイルに分解しており、各ファイルには以下の内容を記載しています。
- クエリーのタイトル
- クエリーURL
- データソース名
- SQL
これらの情報はRedashを利用していると、メタ情報DBに保存されているので特別に情報を付け足したりなどは不要でした。
dbtモデル定義
Analyticsチームがdbt用にモデル定義を作成しているので、dbtのyamlファイルをそのまま保存しています。こちらも既にあるものをそのまま読み込ませただけになります。
Markdownファイル内のSQLコメント
既存のRedashクエリーにはAnalyticsチームがクエリー自体の説明や取得項目、条件の説明など様々な情報をコメントとして付与してくれています。そのため、単純にSQLのみを読み込ませた場合よりも、精度高く回答を生成できるようになっています。
(上手くいかない場合は、SQLをLLMで要約させた文章をMarkdownファイルに含めようかと考えていましたが、それをせずとも十分に利用できる状態でした)
Embedding Modelとチャンキング戦略
S3内のデータをベクトル化して保存する際のEmbedding Modelとチャンキング戦略はそれぞれ以下を設定しています。
| 項目 | 説明 |
|---|---|
| Embedding Model | Amazon Titan Text Embedding v2 |
| チャンキング戦略 | 固定チャンク( 8,192トークン) |
Amazon Bedrockで日本語テキストをEmbedding Modelで扱う場合、「Amazon Titan Text Embeddings V2」と「Cohere Embed Multilingual」が候補になるかと思います。今回は可能な限り、1 Markdwonファイルを1チャンクにまとめたかったため、より多くのトークンを扱える「Amazon Titan Text Embeddings V2」を採用しました。また、同様の理由でチャンキング戦略も記載の設定としています。
クエリーのピンポイント検索
「https://example.com/queries/1234 のクエリーを解説して?」といった質問に対して、該当SQLをベクトル検索で上手くヒットさせることができないという課題がありました。MarkdownファイルにクエリーURLを含めていても、内容の大部分はSQLとなるためベクトル差が大きく検索にヒットしなかったんだと思います。(ハイブリッド検索でも検証しましたが結果は大差のない状況でした💦)
この課題は、Tool Use機能(実装はLangChainを利用しているのでTool Callingですね)を用いてS3バケットからピンポイントで該当のMarkdownファイルを取得させることで解決しました。
RedashのクエリーURLは https://example.com/queries/{クエリーID} という規則で構成されています。また、Markdownファイルは{クエリーID}.mdという命名規則で保存しています。質問文内のクエリーURLから「クエリーID」を抜き出し、直接S3バケットからファイルを取得するToolを実装することで実現しています。
今年の8月に社内で公開してから約1か月くらい経ちましたが、400回くらい利用してもらえているのでまずまずの滑り出しになったかと思います。また、エンジニアではないビジネスサイドのメンバーにも一定利用してもらえています☺️
エンジニアからはこんなコメントをいただきました🙌
慣れている人がやっても結構苦労する、100行ぐらいのSQLなら一発で出してくるので、リリース直後社内にどよめきが起きました(笑) プロダクトのDBに対するSQLを公開することはできないので、BigQueryに保存しているGoogle Analyticsのデータに対してSQLを作成した例で雰囲気が伝わればと思います。

社内公開からまだ1ヶ月が経過したばかりなので、まずは利用状況を蓄積し、回答精度の改善に取り組んでいく予定です。現状は今後の改善案として次のことを検討しています。
1. ドメイン知識の読み込み
別チャットボットであるAI Park Directが参照しているドメイン知識のナレッジベースを読み込むことで、より深いコンテキスト理解が可能になると考えています。
2. dbtモデル定義のピンポイント検索
「このテーブルのこの項目」という伝え方をした場合に、Redashクエリーの時と同様の理由で上手く検索にヒットさせることができていません。dbtのモデル定義もテーブル名でピンポイントに検索できるようにすることで、この問題を解決できるのではと考えています。
3. MCP化によるコーディングでの活用
実際の利用を通じて、SQLからDjango ORMへの変換も結構な精度で実現できることが判明しました。AI AnalyticsをMCP経由で呼び出せるようにすることで、コーディングエージェントからも活用できればと考えています。
今回はAI Analyticsというチャットボットについて紹介しました。
仕組み自体はとてもシンプルで、既存の資産があれば割と簡単に実現できるものかと思います。
もし興味を持たれたら、ぜひ参考にしてみてください。
弊社Analyticsチームの上田がprimeNumber User Group のイベントでAI Analyticsを含めたニーリーのデータ基盤について登壇しましたのでその時のスライドも合わせて参照ください。
{kind=link}