


はじめに
この記事はGaudiy Engineers Advent Calendar 2025の6日目の記事です。
はじめまして。Gaudiy でデータエンジニアをしている miyataku です。
私たちのプロジェクトでは、「BigQuery で分析したデータをアプリケーション側で使いたい」というニーズがありました。
課題となったのは、データ分析基盤が GCP (BigQuery)、アプリケーションが AWS で動いているというマルチクラウド構成 です。プラットフォームをどちらかに統一する案も出ましたが、コストやリスクを試算すると現実的ではありませんでした。
そこで、マルチクラウド環境を維持したまま、BigQuery のデータを AWS 側で活用する仕組み を構築する方針を選択しました。
技術選定から開発まで進めていった結果、いい感じに要件を満たす構成がまとまって、わずか3 週間で完了まで持っていくことができました。
これほど短期間で仕上げられた大きな理由は、技術選定から開発まで Claude Code を積極的に活用した点にあります。
本記事では、そのときの意思決定や構成、AIをどう活用したかなどの裏側をまとめて紹介します。
🔍 この記事のハイライト
- 🔄 データ連携基盤構築:BigQuery → S3 → アプリケーションのデータ連携を短期間で実現
- ⏱️ 開発工数削減:Cloud Run Jobs の採用で 6〜9 日短縮。Go / Docker の既存スキルのみで対応可能
- 🔐 セキュアな認証:Cloud Run OIDC × AWS STS でマルチクラウド認証を実現(WIF構築不要)
- 💰 高いコスト効率:数百万ユーザー規模のデータを月額コスト数ドルで処理
- 🤖 AI 活用の工夫:技術選定や実装パターン検討で効率化を実現
- 📚 ドキュメント戦略:spec / research の分離で新メンバーのキャッチアップを大幅に高速化
1. 背景と課題
実現したかったことはシンプルで、BigQuery で分析・集計したユーザーの記録や行動履歴を、API 経由でアプリケーションに提供することです。
これができれば、よりパーソナライズされた体験を提供できます。
ただ、実際にやろうとすると、2 つの壁にぶつかりました。
マルチクラウド認証をどうするか
データは GCP(BigQuery)にあって、アプリケーションインフラは AWS(ECS/S3)にある。
つまり GCP 側から AWS の S3 に安全にアクセスする必要があります。
アクセスキーみたいな長期秘密情報は管理リスクが高いので避けたいですし、かといって認証基盤を新たに構築・運用するコストもできるだけ抑えたい。
数百万ユーザー分のデータを高速に処理するには
1 日 1 回、数百万ユーザー分のデータを全件更新する必要があります。
Cloud Run のメモリ・CPU 制限の中で、並列処理をうまく使って高速化しつつ、コストも最適化しないといけません。
マルチクラウドのままいくか、統合するか
最初はチーム内でも「マルチクラウドって運用複雑じゃない?どっちかに統合した方がいいのでは?」という意見がありました。
AWS 統合案(BigQuery → Redshift に移行)や GCP 統合案(ECS → Cloud Run に移行)も一応検討しましたが、どちらも既存システムの大規模な移行が必要で、移行期間やビジネスリスクを考えると現実的ではありませんでした。
となると、マルチクラウドのままでいくことになるのですが、「アクセスキーの管理コストが心配…」という懸念がありました。
でも実際に検証してみたら Cloud Run のデフォルト OIDC だけで AWS 認証が完結して、Workload Identity Federation(WIF)の構築も不要で、意外とシンプルに構築できました。
この検証結果を受けて、マルチクラウド構成を維持する方針を確定。
データ連携基盤の構築を進めて、短期間で完了まで持っていくことができました。
2. 技術選定とアーキテクチャ
今回構築したのは、BigQuery(データウェアハウス)から S3(データストア)を経由してアプリケーションにデータを提供する、リバースETL(Reverse ETL) の仕組みです。
要するに、BigQuery で分析・集計したデータを、アプリケーション側で使えるようにする流れになります。
全体構成
先ほど挙げた 2 つの課題(マルチクラウド認証と大量データ処理)を解決するために、こちらの構成を選定しました。
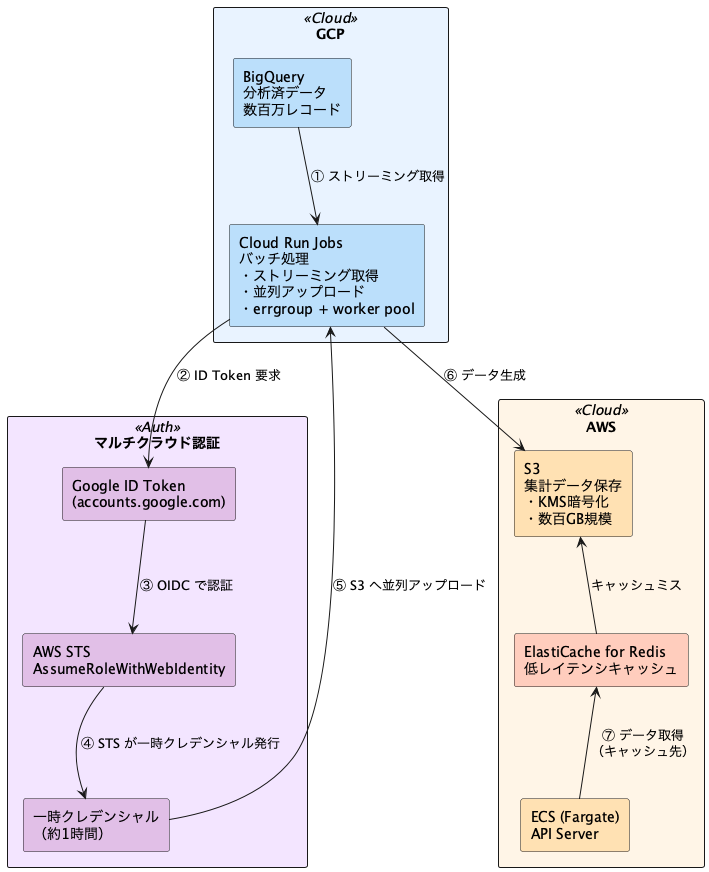
データストアは S3 + ElastiCache に決定
データストア選定では、2つの観点を重視しました。
1つ目は、アプリケーション側が ECS に決まっているため、ECS から参照しやすい形であること。
2つ目は、BigQuery から取得したデータを転送する集計ジョブからの一括更新のしやすさです。
データストアの候補としては S3、DynamoDB、Aurora の 3 つを検討しました。最終的に選んだのは S3 + ElastiCache for Redis の組み合わせです。
データ特性を整理してみると、読み取り専用・日次更新・検索不要というパターンなので、RDB の利点(トランザクション、JOIN)も DynamoDB の利点(低レイテンシ書き込み)もあまり活かせないことが分かりました。
むしろ「安価に大量データを長期保管する仕組み」が最適です。
当初は「数百万ユーザーのデータ扱うなら RDB(Aurora)の方が安全ではないか?」という意見もありましたが、よくデータ特性を整理すると以下のことがわかりました。
- トランザクション不要:1 日 1 回の全件置換だし、ACID 特性いらない
- JOIN 不要:もう BigQuery で集計済みのデータを転送するだけ
- スキーマ変更の柔軟性:S3 なら JSON 形式でスキーマフリー。RDB だと ALTER TABLE が必要
- コスト:Aurora は月額数十ドル〜、S3 は月額数ドル程度
こういった理由で RDB は選択肢から外れました。
さらに、「RDB だと高速だが、S3 だと遅い」という懸念も、ElastiCache をキャッシュとして使うことで解決できました。
| 観点 | S3 の優位性 |
|---|---|
| ストレージコスト | DynamoDB と比較して大幅に安価。数百万ユーザー規模でも月額コストを抑えられる |
| アクセスパターン | 日次全件更新・読取専用に最適 |
| バージョン管理 | S3 標準機能で過去データ保持が容易(RDB は履歴テーブル設計が必要) |
| レイテンシ | S3 単体では数十〜百ms程度だが、ElastiCache(サブミリ秒)で十分カバー可能と判断 |
ジョブ実行環境は Cloud Run Jobs で
ジョブ実行環境はデータソースとして BigQuery がメインになるだろうとは想定していましたが、将来的に他のデータソースも扱う可能性があったため、特定のデータソースに依存しない柔軟な仕組みを選びたいと考えました。
ジョブ実行環境の候補は Cloud Run Jobs と Vertex AI Pipelines の 2 つ。最終的に選んだのは Cloud Run Jobs です。
| 観点 | Cloud Run Jobs | Vertex AI Pipelines | 判定 |
|---|---|---|---|
| 開発工数 | 短期間で対応可能 | パイプライン定義・DSL学習が必要 | ✅ 大幅に削減 |
| コスト | 低コスト | 相対的に高コスト | ✅ 圧倒的に低コスト |
| アーキテクチャ | コンテナ 1 つで完結(修正も容易) | DSL 学習が必要 | ✅ シンプル |
チームが既に持っている Go / Docker のスキルを中心に開発できて、パイプライン定義や DSL の学習が不要だったのが決め手でした。
結果として、開発工数を大幅に削減できました。
3. 実現のポイント
BigQuery からデータをストリーミングで取得
数百万ユーザーのデータを一気にメモリに読み込んだら、OOM(Out Of Memory)で落ちるリスクがあります。
なので、Query.Read() が返す RowIterator を使って、ストリーミングで 1 件ずつ処理する方式にしました。
// BigQuery クエリを実行
query := client.Query("SELECT ...")
it, err := query.Read(ctx)
if err != nil {
return fmt.Errorf("failed to read query: %w", err)
}
// RowIterator でレコードを1件ずつ処理(全件メモリに載せない)
for {
var row MyStruct
err := it.Next(&row)
if err == iterator.Done {
break
}
if err != nil {
return fmt.Errorf("iterator error: %w", err)
}
if err := processRow(ctx, row); err != nil {
return err
}
}ポイント:
- RowIteratorは内部でページングを行うため、数百万レコードでも全データをメモリに保持する必要がない
- 常に処理中の1レコード分のみがメモリに載るため、Cloud Runのメモリ制限内で安定した処理が可能
マルチクラウド認証は意外とシンプルだった
結論から言うと、Cloud Run のデフォルト OIDC トークン(Issuer: accounts.google.com)を使うだけで完結しました。
最初は「Workload Identity Federation(WIF)の構築が必須では?」と思ってましたが、AWS は accounts.google.com を WebIdentity Provider として直接扱えるため、WIF Pool の作成は不要でした。
AWS 側の IAM Role(Trust Policy)
{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Principal": {
"Federated": "accounts.google.com"
},
"Action": "sts:AssumeRoleWithWebIdentity",
"Condition": {
// Cloud Run の ID Token を検証する条件を設定
// 詳細は AWS STS と Google Cloud OIDC のドキュメントを参照
}
}
]
}ポイントは "Federated": "accounts.google.com" の設定で、これだけで Cloud Run のデフォルト OIDC を使えます。
Condition 部分は環境によって異なるため、AWS STS と Google Cloud OIDC のドキュメントを参照してください。
認証の有効期限について: AWS STS が発行する一時クレデンシャルは 1 時間で期限切れになります。
今回はクレデンシャルをキャッシュし、期限切れ 10 分前に自動更新する仕組みを実装しました。
並列アップロードで高速化
BigQuery からのストリーミング取得と S3 への並列アップロードを組み合わせて、errgroup.WithContext で制御しました。
並列数を 10〜100 で調整して、1 日 1 回の全件更新という要件を十分満たせる性能を実現できました。
ただ、高並列で S3 にアクセスする場合、Go のデフォルト HTTP クライアント設定がボトルネックになるので、接続プールを拡張しました。
httpClient := &http.Client{
Transport: &http.Transport{
MaxIdleConns: 200,
MaxIdleConnsPerHost: 200,
IdleConnTimeout: 90 * time.Second,
},
}ポイント:
MaxIdleConnsPerHost:デフォルトは2ですが、並列数に合わせて200に拡張- これにより、接続の再利用(Keep-Alive)が効き、高速かつ安定した処理が可能になります
4. AI をどう活用したか
今回のマルチクラウド構成のデータ連携基盤では、Claude Code を活用して、技術選定から開発まで短期間で完了できました。
技術選定の壁打ち相手として
技術選定を AI に相談するとき、一番大事なのは前提となる要件を明確に伝えることです。
データ特性、アクセスパターン、パフォーマンス要件を構造化して提示すると、AI が適切な比較軸で回答を返してくれます。
# 技術選定:データストアの選定
## 集計対象の情報
- 対象ユーザー数: 数百万
- 更新頻度: 1日1回(全件更新)
- アクセスパターン: 読み取り専用
## 比較観点
1. 月額コスト
2. 開発工数
3. 性能
## 比較対象
- S3 + ElastiCache
- DynamoDB
- Auroraこの形式で依頼すると、AI が各候補を一貫した観点で比較してくれて、意思決定の質が上がりました。
マルチクラウド認証の構築など、初めて扱う技術要素についても、ベストプラクティスを含むサンプルコード付きで回答が返ってくるので、方針を素早く固められました。
AI 活用で重要なのは、入力の厳格さと出力への深掘りの両立です。
生成されたコードやアーキテクチャ案に対して「このエラーケースは?」「パフォーマンスは?」「この情報は本当に正しい?」と繰り返し問いかけ、公式ドキュメントで裏取りしながら品質を高めていきました。
AI はハルシネーション(誤った情報の生成)もあるため、出力を鵜呑みにせず、批判的に検証することが不可欠です。
意思決定に “唯一の正解” はありません。だからこそ、意思決定理由を明確にし、曖昧さを残さないことが重要です。
AI は選択肢の整理や情報収集を効率化してくれる存在として活用しました。
コード生成の活用
AI によるコード生成は、errgroup による並列処理や HTTP クライアントの接続プール設定など、Go のベストプラクティスに沿った実装パターンを素早く提案してくれるため、調査時間の短縮に役立ちました。
ただし、初期段階では失敗もありました。
設計方針を明確にせず「BigQuery から S3 にデータを転送する処理を書いて」とだけ依頼したら、レビューで大量の修正が発生。
エラーハンドリング、ログ出力、インターフェース設計が曖昧なまま生成されたので、開発時間よりもレビュー対応時間の方が長くなってしまいました。
対策として、開発前にエラーハンドリングポリシー、ログ出力ポリシー、インターフェース設計などを CLAUDE.md に記載するようにしたところ、レビューコメントが大幅に削減されました。
プロジェクト固有のルールを事前に伝えることで、最初から本番投入レベルのコードが生成されるようになりました。
ドキュメント管理の工夫
AI を活用して技術選定を行うと、どうしても膨大な検討ログが生成されます。
これをそのままチームに共有すると、必要な結論が埋もれ、読むのに時間がかかり、レビューが難しくなります。
解決策:spec / research 分離
- docs/spec/(開発仕様書:結論): A4 1〜2 枚に収まる簡潔な仕様書。What(何を作るか)、Why(なぜ必要か)、How(どう作るか)のみを記載。検討過程は含めない。
- docs/research/(根拠の記録): 詳細な検討記録。候補技術の比較、コスト試算、実測ベンチマーク、AI との議論ログ、不採用案の理由を記載。
効果:
- 新メンバーは spec(A4 1-2 枚)を読めば全体を把握でき、research を最初から読む必要がない
- 意思決定の理由が research に残るので透明性が保たれる
- PR では spec だけ確認すればよく、詳細は必要に応じて research を参照
- 方針転換の判断がしやすい:research に「なぜその選択をしたか」が残っているので、状況が変わったときに「前提条件が崩れた」と気づきやすく、適切なタイミングで方針を見直せる
この分離により、「新メンバーは spec を読むだけで開発開始」「マネージャーは結論だけ見れば十分」「詳細が必要な時のみ research を参照」という効率的なワークフローが実現しました。
さらに、意思決定の根拠が明確に残るので、半年後・1年後に「なぜこの構成にしたんだっけ?」と振り返るときにも役立ちます。
5. やってみて分かったこと
マルチクラウドは思ったよりシンプルだった
Cloud Run のデフォルト OIDC と AWS STS を組み合わせることで、追加インフラなしでクラウド間の安全な認証を実現できました。
Workload Identity Federation(WIF)が不要だったのは大きな発見で、構築も思ったよりずっとシンプルでした。
ストリーミング取得 × 並列処理で高速化
BigQuery のストリーミング取得(RowIterator)でメモリ使用量を抑えつつ、S3 へのアップロードは worker pool と errgroup を組み合わせて並列化。
さらに HTTP コネクションプールを適切に調整したことで、安定して高いスループットが出せるようになりました。
ドキュメント管理とAI活用はセットで考える
spec / research の分離で、チーム全体での情報共有の質が大幅に向上しました。
新メンバーが短時間で追いつけるし、認識のズレもなくなるし、仕様変更点も分かりやすくなりました。
AI を使うと検討ログが膨大になりがちですが、この分離戦略で整理することで、必要な情報に素早くアクセスできるようになります
6. おわりに
マルチクラウド構成って複雑そう…と最初は不安でしたが、実際に検証してみると Cloud Run の OIDC + AWS STS だけでクラウド間認証が完結して、思ったよりシンプルに構築できました。
データストアは S3 + ElastiCache、ジョブは Cloud Run Jobs という構成で、短期間で完了できました。
Go と Docker の既存スキルだけで対応できたのも大きかったです。
Claude Code を技術選定の壁打ちに活用したことで開発スピードが上がりました。
要件を構造化して AI に相談することで選択肢の整理が効率化され、意思決定の材料を素早く集められました。
ただし設計方針や最終判断は人間が行う必要があります。
最初から完璧な指示を出すのではなく、AI の出力に対して疑問を投げかけ、改善を重ねていく対話プロセスが、品質の高い成果物につながります。
マルチクラウドや AI 活用の開発プロセスで悩んでいる方の参考になれば幸いです。
#GauDev Advent Calendar 2025、明日の担当はYuseiWhiteさんです!
{kind=link}