

はじめに
こんにちは!株式会社iimonでエンジニアをしている遠藤です。
本記事は iimonアドベントカレンダー4日目の記事です!
もう少しでクリスマス、そして年末が近づいてきましたね。
あっという間に新卒3年目も終わりを迎えそうで、時の流れの速さに驚いています。
速さといえば、近年の生成AIの進化の速さにも驚かされます。
昨年頃から業務でも生成AIを使う機会が増え、Claude や ChatGPT、GitHub Copilot などに触れることが日常的になってきました。
その中で、「プロンプトはこう書くと良い」「こういう工夫が効く」といったいわゆるプロンプトエンジニアリング的な話もよく耳にします。
ただ、最近のモデルは非常に高性能になっており、単純なタスクならある程度雑な指示でも動いてくれる印象があります。
「プロンプトの工夫って必要なの?」と思うこともありました。
お恥ずかしながら、そもそもLLMがどうやって動いているのかを全く知らないまま使っていたので、仕組みを理解すれば、プロンプトの工夫が必要な理由も少し分かるのではないか。そう思って、調べてみることにしました!
この記事は、LLMの基本的な仕組みを学んで、自分なりに理解したことをまとめたものです。(厳密な技術解説や最新研究の網羅ではありません。)
同じようにLLMの仕組みがよく分からないまま使っている方に向けて、入門的な内容になっています。
プロンプトエンジニアリングとは
プロンプトエンジニアリングとは、LLM(大規模言語モデル)から望ましい出力を得るために、入力(プロンプト)を工夫する手法のことです。
例えば、書籍『生成AIのプロンプトエンジニアリング』の著者である Michael Taylor 氏は、ブログ記事「Prompt Engineering: From Words to Art and Copy」の中で、
「テクニックを覚えるのではなく、AIとの普遍的な付き合い方に注目すべきだ」と述べています。
その実践指針として挙げられているのが「プロンプティングの5原則(Five Principles of Prompting)」です。
(以下、DeepL にて日本語訳)
- 方向性を示す:望ましいスタイルを詳細に記述するか、関連するペルソナを参照する。
- 形式を指定する:従うべきルールと、応答に必要な構造を定義する。
- 例を提供する:タスクが正しく実行された多様なテストケースを挿入する。
- 品質評価:誤りを特定し応答を評価し、パフォーマンスを左右する要因を検証する。
- 分業化:タスクを複数のステップに分割し、複雑な目標達成のために連鎖させる。
※ 2に関して、元記事では「ChatGPTのようなもので遊んでいるときは、応答の構造はそれほど重要ではありません」とも書かれており、形式の指定はアプリケーションでの活用など出力を安定させたい場面において重要になるという位置づけのようです。
Claude の開発元である Anthropic の公式ガイド「プロンプトのベストプラクティス」は、「Claude 4.x モデル向けの具体的なプロンプトエンジニアリング技法」として書かれていますが、「明確な指示」「具体的な例」「構造化」「段階的なアプローチ」といった要素が挙げられており、上記の原則と共通点も見られます。
LLMの仕組みをざっくり理解する
ここからは、プロンプトがどのようにモデル内部で処理されているのかを理解するための、ざっくりとした整理です。
厳密な数学的説明ではなく、イメージを掴むことを目的にしています。
LLMとは
LLM(Large Language Model:大規模言語モデル)は、入力されたテキストをもとに、次に続くテキストを確率的に生成するモデルです。
ChatGPTやClaudeが自然な文章を返すのは、この“次を予測する”仕組みによるものです。
LLMの基本的な流れは以下の2つに分けられます。
トークン化
入力された文章は、まず「トークン」と呼ばれる単位に分割されます。この処理を「トークン化(tokenization)」と呼び、テキストをモデル内部で扱いやすい数値に変換する役割を持ちます。
トークンは必ずしも単語と一致しません。
例えば、英語の “unhappiness” は “un” と “happiness” に分割されることがありますし、日本語の「プログラミング」もモデルによって複数のトークンに分けられることがあります。
この分割方法はモデルが採用しているトークナイザー(例:BPE や SentencePiece など)によって異なります。
GPT 系モデルの場合、OpenAI Tokenizer を使うと、入力したテキストがどのようにトークンに分割されるかを視覚的に確認できます。
例として「今日の天気は雨です。」を入力すると、いくつかのトークンに分割されます。
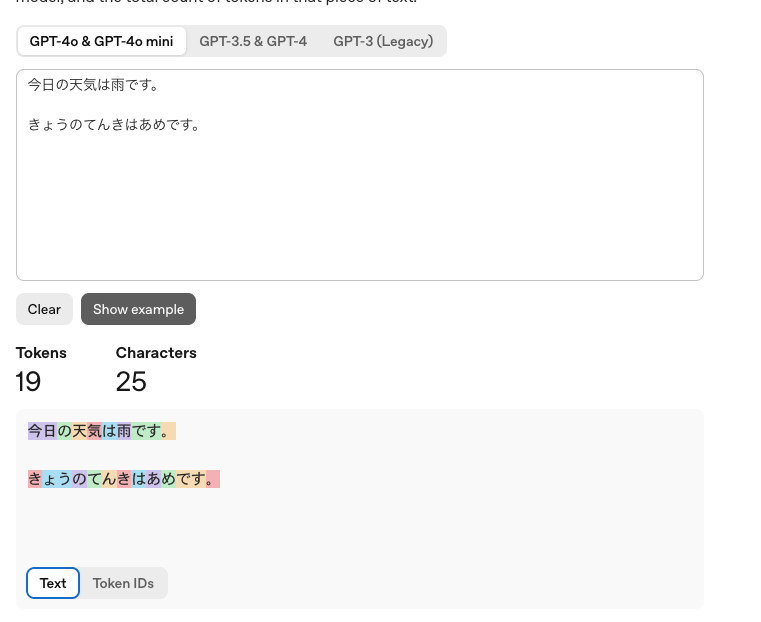
そして、各トークンはモデル内部で一意に割り当てられたトークンID(整数)に変換されます。

今回は詳細に触れませんが、整数化されたトークンは埋め込み層(Embedding)でベクトル化されます。
その後、位置情報(Positional Encoding / Rotary Positional Embedding(RoPE)など)が加えられ、Transformerによる自己注意(Self-Attention)機構を通じて文脈情報が付与されます。
次のトークンを予測する
Transformerによって文脈が理解されたあと、モデルは「この文脈の次に来るトークンは何か?」を確率的に予測します。
その確率分布に基づき、最も確率の高いトークン(あるいは確率分布に従ってサンプリングされたトークン)が選ばれます。
例えば、「今日の天気は」というテキストが入力された場合、LLMは次に来るトークンとして「晴れ」「雨」「曇り」などを候補として予測します。
そして、予測したトークンを出力に加え、また次のトークンを予測する。これを繰り返すことで、文章が生成されていきます。
入力: 「今日の天気は」 ↓ 次のトークンを予測 出力: 「雨」 入力: 「今日の天気は雨」 ↓ 次のトークンを予測 出力: 「です」 入力: 「今日の天気は雨です」 ↓ 次のトークンを予測 出力: 「。」 最終出力: 「今日の天気は雨です。」
※ 実際の内部処理ではベクトルとして扱われていますが、ここではイメージしやすいようにテキストで表現しています。
TemperatureやTop-p(Nucleus Sampling)などのパラメータは、この確率分布の「どの程度多様にサンプリングするか」を制御するものです。
プロンプトの工夫が必要な理由
仕組みを学んで分かったのは、LLMは「確率的に次のトークンを選んでいる」ということでした。
つまり、入力によって確率分布が変われば、選ばれるトークンも変わります。
プロンプトで条件を与えることで、モデルが文脈上「適切だと判断するトークン」の確率が相対的に高まり、結果として出力の方向性をある程度“誘導”できます。
そのため、プロンプトで「範囲を絞る」ことに意味があるのだと理解しました。
例えば、「説明して」だけだと、どんな文体でも候補になります。
でも、「小学生にも分かるように説明して」と書けば、より平易な語彙や文構造が選ばれやすくなります。
まとめ
今回は、基本的なLLMの仕組みをざっくり学んでみました。
もちろん、今回触れていない技術やモデルごとの特性も関係してくると思いますが、仕組みを知ったことで、プロンプトの工夫が必要な理由を自分なりに納得できました。
まだ入り口に立った程度(締め切りギリギリで、書籍もかなり読み飛ばしました…😢)ですが、AI時代に取り残されないように、これからも試行錯誤しながら勉強していきたいです。
同じようにLLMの仕組みがよく分からないまま使っている方に、この記事が少しでも参考になればうれしいです。
記事の内容に誤りがございましたら、ご指摘いただけますと幸いです!
最後まで読んでくださりありがとうございます!
弊社ではエンジニアを募集しております。
ご興味がありましたらカジュアル面談も可能ですので、下記リンクより是非ご応募ください!
iimon採用サイト / Wantedly
明日はhiga さんの記事です!
どんな記事を書いてくださるか楽しみです!
参考資料
Jay Alammar,Maarten Grootendorst著中山 光樹訳(2025)『直感 LLM
―ハンズオンで動かして学ぶ大規模言語モデル入門』オライリー・ジャパン
Prompt Engineering: From Words to Art and Copy – Saxifrage Blog
{kind=link}