

こんにちは。マイクロアドで機械学習エンジニアをしている前田、簀河原です。
この記事では、マイクロアドにおける Click Through Rate (CTR) 予測の精度および安定性向上のために Target Encoding を活用した事例を紹介します。
Real Time Bidding (RTB) では下図のように、広告主とメディア間でリアルタイムにオークションが開催され、オークションに勝利した広告がメディアに表示されます。
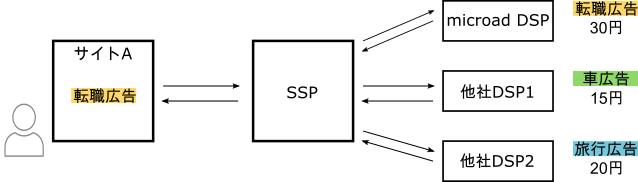
マイクロアドでは現在オークションの入札額は次のように予測 CTR と目標 CPC (Cost per Click) の積に依存する形で決定しています。 Zhang, 2014
CTR は広告が表示されたときにクリックされる確率で、 過去の配信ログから機械学習モデルを学習して予測しています。オークションの勝率・配信効果に直結するため、正確な CTR を予測することが求められます。
CTR 予測に関する過去のマイクロアドの取り組みはこちら*1*2*3
過去の配信ログはテーブル形式のデータで、大半が広告IDや広告配信先ドメインなどといったカテゴリ変数になっています。
カテゴリ変数を多くの機械学習モデルが取り扱える数値表現に変換する必要があります。
カテゴリ変数を数値表現に変換する代表的な方法はいくつかあり、One-hot Encoding や Label Encoding などがありますがここでは Target Encoding と呼ばれる手法についての一般的な紹介をします。
Target Encoding はカテゴリカル特徴量を、そのカテゴリが与えられたときの目的変数(CTR 予測ならばクリックしたか否か)の平均値で置き換える手法です。
Liudmila et al., 2019を参考にしてやや形式ばった表現をすると、以下の通りです。
データセット: に対して、
番目の訓練データにおけるカテゴリカル特徴量
を
とします。
Target Encoding は をそのカテゴリが与えられた条件下でのターゲットに関する統計量
で置き換える手法を Target Encoding と呼びます。
この をどのように計算して近似するかによって、Target Encoding の種類が分かれています。
以下では代表的な Target Encoding 手法を紹介します。
Greedy Target Encoding
自身を含めた全ての訓練データを使って を計算します。
と同じカテゴリ値を持つデータが少ない場合に
が不安定になるのを防ぐためにナイーブな平均ではなく事前分布
(基本的にはデータセット全体の
の平均値)を用いたベイズ平均を取る場合が多いです。
最も単純な Target Encoding で、リークによる汎化性能の低下を引き起こす可能性が高いため基本的にはNGな手法とされています。
エンコード結果の例。
エンコード前
| 広告ジャンル | Click1 | |
|---|---|---|
| 1 | 美容 | 0 |
| 2 | アニメ・漫画 | 1 |
| 3 | 美容 | 1 |
| 4 | アニメ・漫画 | 0 |
| 5 | アニメ・漫画 | 1 |
エンコード後
| 広告ジャンル | Click | |
|---|---|---|
| 1 | 0.5 | 0 |
| 2 | 0.666… | 1 |
| 3 | 0.5 | 1 |
| 4 | 0.666… | 0 |
| 5 | 0.666… | 1 |
ここでは に
が含まれていることをリークと呼ぶことにします。
Leave-one-out Target Encoding
自身以外のデータを使って Target Encoding を行う手法です。
ここで.
エンコード結果の例。
エンコード前
| 広告ジャンル | Click | |
|---|---|---|
| 1 | 美容 | 0 |
| 2 | アニメ・漫画 | 1 |
| 3 | 美容 | 1 |
| 4 | アニメ・漫画 | 0 |
| 5 | アニメ・漫画 | 1 |
エンコード後
| 広告ジャンル | Click | |
|---|---|---|
| 1 | 0 | 0 |
| 2 | 0.5 | 1 |
| 3 | 1 | 1 |
| 4 | 1 | 0 |
| 5 | 0.5 | 1 |
自身のラベルの情報を使っていないためリークが発生しないように見えますが 内に
が出現しているため、実際にはリークが発生しています。
K-fold Target Encoding
データセットをK個に分割して、交差検証の要領で Target Encoding を行う手法です。
ここで は
番目のデータを含む分割後のデータ数を表す。
(1, 2) を , (3, 4, 5) を
としてデータセットを2分割したときのエンコード結果の例
エンコード前
| 広告ジャンル | Click | |
|---|---|---|
| 1 | 美容 | 0 |
| 2 | アニメ・漫画 | 1 |
| 3 | 美容 | 1 |
| 4 | アニメ・漫画 | 0 |
| 5 | アニメ・漫画 | 1 |
エンコード後
| 広告ジャンル | Click | |
|---|---|---|
| 1 | 1 | 0 |
| 2 | 0.5 | 1 |
| 3 | 0 | 1 |
| 4 | 1 | 0 |
| 5 | 1 | 1 |
Leave-one-out Target Encoding と同様に、には
の情報が含まれているため、厳密にはリークが発生しています。ただしその影響は Leave-one-out Target Encoding よりも小さいとされます。
Holdout Target Encoding
モデルの訓練データセットとは別に Target Encoding 用のデータセットを用意する手法です。
エンコード用データセット
| 広告ジャンル | Click | |
|---|---|---|
| 1 | 美容 | 0 |
| 2 | 美容 | 0 |
| 3 | 美容 | 1 |
| 4 | アニメ・漫画 | 0 |
| 5 | アニメ・漫画 | 1 |
上記のエンコード用データセットを与えた場合のエンコード結果の例。
エンコード前
| 広告ジャンル | Click[^1] | |
|---|---|---|
| 1 | 美容 | 0 |
| 2 | アニメ・漫画 | 1 |
| 3 | 美容 | 1 |
| 4 | アニメ・漫画 | 0 |
| 5 | アニメ・漫画 | 1 |
エンコード後
| 広告ジャンル | Click | |
|---|---|---|
| 1 | 0.33… | 0 |
| 2 | 0.5 | 1 |
| 3 | 0.33… | 1 |
| 4 | 0.5 | 0 |
| 5 | 0.5 | 1 |
リークは発生しませんが、実用上は訓練に使用できるデータ数が少なくなってしまうという問題を抱えています。
Ordered Target Encoding
データセットに仮の時系列順序を与え、自身より過去のデータのみを使って Target Encoding を行う手法です。
以下のように仮の順序を与えた場合のエンコード結果の例。
エンコード前
| 仮の順序 | 広告ジャンル | Click | |
|---|---|---|---|
| 1 | 0 | 美容 | 0 |
| 2 | 1 | アニメ・漫画 | 1 |
| 3 | 2 | 美容 | 1 |
| 4 | 3 | アニメ・漫画 | 0 |
| 5 | 4 | アニメ・漫画 | 1 |
エンコード後
| 仮の順序 | 広告ジャンル | Click | |
|---|---|---|---|
| 1 | 0 | –2 | 0 |
| 2 | 1 | – | 1 |
| 3 | 2 | 0 | 1 |
| 4 | 3 | 1 | 0 |
| 5 | 4 | 0.5 | 1 |
リークを発生させずに全てのデータを訓練に使用できますが、若い順序を与えられたデータについては Target Encoding の結果が不安定になります。
このように Target Encoding は強力な手法ですが、手法によってはリークやエンコード結果の安定性などの問題があるため取り扱いが比較的難しいエンコーディング手法といえます。
ここからは Target Encoding の活用イメージを掴んでもらうために、マイクロアドにおける実事例を1つ紹介します。
問題設定: 広告枠の Target Encoding
広告枠とは、メディアに設置されている広告の表示領域のことを指します。
送られてくる入札リクエストには広告枠の ID が含まれており、広告枠も CTR を決定付ける1つの要素なので、CTR 予測モデルの特徴量として活用されています。
一般的に広告枠は
- その枠が存在するメディアの性質や表示位置により、平均的な CTR の傾向差がある (常日頃から CTR が高い枠もあれば低い枠もある)
- 長期間安定して同じ広告枠から入札リクエストがあるわけではなく、ある日突然オークション市場に新規枠が出現する(逆に消えることもある)
の特徴があります。
そのため、平均的な CTR から逸脱した新しい枠が出現した場合、その枠のリクエストについて予測 CTR と真の CTR が乖離することによる配信効果の悪化を確認していました。
一方で、時間が経過しさえすれば実績(過去ログ)が蓄積されて学習データセットに追加されるため、安定的な予測が可能になります。
このような背景から、
- 新規枠の 0 もしくは少ない実績は信用しない。
- 新規枠の配信が十分に出れば実績を信用し始めても良い。
をモデルがきちんと解釈して正しい予測ができるように、枠ID をカテゴリ変数として扱うのではなく、Target Encoding によるエンコード値を活用することにしました。
Ordered Target Encoding x Smoothing
要件を整理すると、
- 過去の実績を基準にする → Ordered Target Encoding の活用
- 新規枠の配信期間によって信用度を変えたい → Smoothing 3 の活用
が自然な発想になります。
数式に落とし込むとこうです:
さて、数式の解説ですが、
になります。
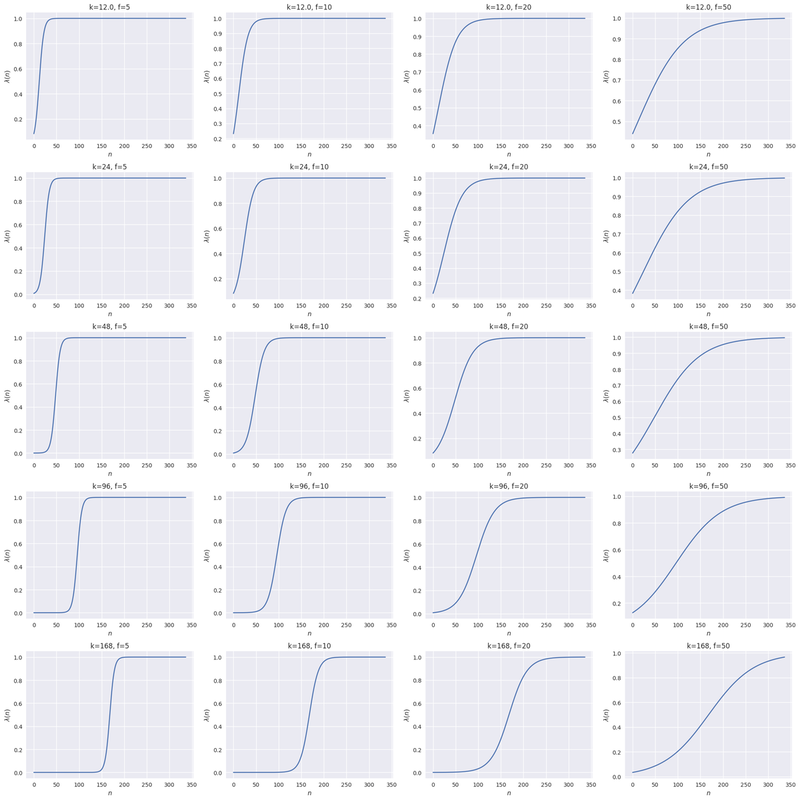
ハイパーパラメータの決定
信頼関数 $\lambda(n)$ は、その定義から、
: 信頼するには最低限どれくらいの実績確認時間
が必要か
: 信頼度 0 → 1 の崖をハードにするかソフトにするか
を制御できます。最適な の選択やその方法はタスクによって異なりますが、今回は経験的に
を決めた上でのグリッドサーチで決定しました。
CTR予測の改善
この改善施策は既に安定版として広告配信に活用されており、
- 確認されていた新規枠に対する問題が目立たなくなった
- 配信効果の改善: 最大で CTR は +5% の改善、CPC (コスト単価) は 1% の削減
を確認しています。
機械学習エンジニア絶賛採用中
最後に、マイクロアドでは問題設定からサーベイ、開発・運用まで裁量を持ってチャレンジしたいという機械学習エンジニアを募集しています。
ご興味あれば是非以下の採用ページからご応募ください!
参考文献
Optimal Real-Time Bidding for Display Advertising, Zhang, 2014
CatBoost: unbiased boosting with categorical features, Liudmila et al., 2019
{kind=link}