


はじめに
こんにちは!プラットフォーム共通基盤グループでエンジニアをしている和田です。最近、開発をしている中で、何が、いつ、どの順番でタスクが実行されるかを明確にして、実行状況を監視しつつ自動化したいというニーズがでてきました。そこで調査を進めたところ、Apache Airflowは多くの企業で利用されており、有力な候補だと考えました。
Apache Airflowって何?
Airflowは、ざっくり言うと、データ処理とか定期ジョブを自動でいい感じに回してくれる仕組みです。たとえば、「朝6時にAPI叩いてデータ取る → 加工する → 結果をDBに突っ込む → Slackに通知」のような流れを全部まとめて管理できます。cronなどで書くと依存関係や失敗時の再実行が面倒ですが、Airflowはそれを「DAG」という形で整理して簡単に管理できます。
基本の考え方
DAG(Directed Acyclic Graph)
DAGはタスクの流れ図で、どのタスクがどの順番で動くかを矢印でつなげ非巡回のタスクの順番を図示したものです。「非巡回」ってのは、ループしないという意味で、「A→B→C」で終わり、Aに戻ったりしないということです。
タスク
DAGを構成する個々の処理のことです。たとえば「データをS3から取る」とか「Python関数を実行」とかで、この1個1個をOperatorというテンプレートで作ります。
Operator
Operatorには様々なものがあり、
PythonOperator:Python関数を動かすBashOperator:bashコマンドを動かすEmailOperator:メール送る
他にも「GoogleCloudStorageOperator」や「SlackWebhookOperator」などの専用のものもあります。便利ですね。
Airflowの中身(ざっくり構成)
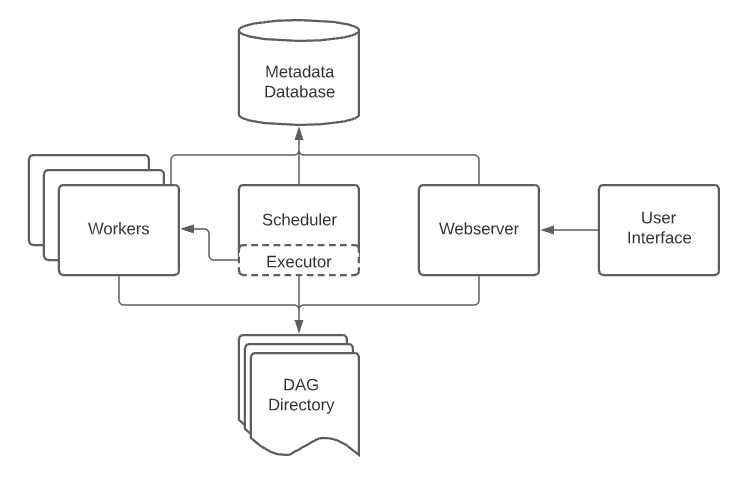
| コンポーネント | 役割 |
|---|---|
| Webserver | Web UI。DAGの状態とかログを見たり、手動実行したりできる。 |
| Scheduler | DAGのスケジュールを見て「そろそろこのタスク走らせるか」を判断して起動するもの。 |
| Executor | 実際にタスクを動かす実行エンジン。ローカルで動かすか、CeleryやKubernetes使うかでスケールが変わる。 |
| Metadata DB | DAGの状態とかタスクの履歴を全部保存しておくDB。 |
これらが連携して、Airflowが動きます。
実際に動かしてみる
公式チュートリアルに基づいて簡易実装してみました。
1. 公式 compose の取得
この compose は CeleryExecutor 構成で、webserver / scheduler / worker / triggerer / postgres / redis (/ flower 任意) が一式そろってるため、こちらを取得してきました。
curl -LfO 'https://airflow.apache.org/docs/apache-airflow/3.1.0/docker-compose.yaml'
2. 共有ディレクトリを用意(DAG/ログ/プラグイン/設定)
mkdir -p ./dags ./logs ./plugins ./config
3. 権限用の .env を置く
公式がLinuxは推奨しています。僕はMacOSでなくても動きますが、upした際に警告がでてきて毎回警告を見るのも嫌だったので一応実行しました。
-
macOS:なくても動きますがが、警告を消したいなら固定でOKです。
echo 'AIRFLOW_UID=50000' > .env -
Linux:自分のUIDを入れる(ログ・設定書き込みの権限対策)
echo "AIRFLOW_UID=$(id -u)" > .env
4. 初期化(DB マイグレーション & 初回ユーザー作成)
docker compose up airflow-init
5. 起動
Web UI は http://localhost:8080で起動します。初期ユーザーは airflow / airflowです。
docker compose up -d docker compose --profile flower up -d
6. 動作確認
/dags/hello.py を作るだけでUIに反映されます。これで1つのノードを作成できました。すごく簡単…。
コードは、直感的でわかりやすいですが、catchupがわからなかったので調べました。DAGを新しくデプロイした際に過去分の実行が出来る機能のことで、catchup=Trueとすることで、過去のDAGが実行されます。catchup=Falseは、過去のDAGが全く実行されないと思いましたが、そうではなく、現在での最新のinterval完了分のみを実行するらしいです。
from airflow import DAG from airflow.operators.python import PythonOperator from datetime import datetime def say_hello(): print("Hello Airflow!") with DAG("hello_dag", start_date=datetime(2025,1,1), schedule="@daily", catchup=False): PythonOperator(task_id="hello", python_callable=say_hello)
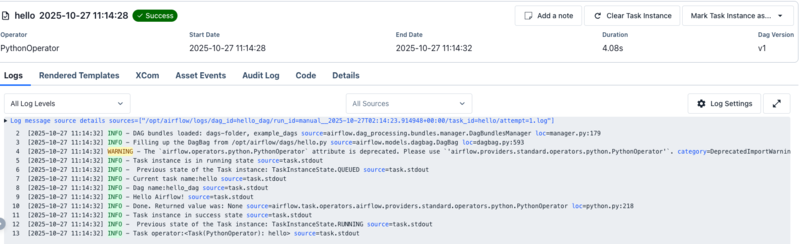
動作確認は UI 上で行います。DAG 画面から「Runs」を開き、対象の Task Instance を選択して「Logs」タブを確認します。ログに「Hello Airflow!」と表示されていれば、正常に実行されていることが確認できます。
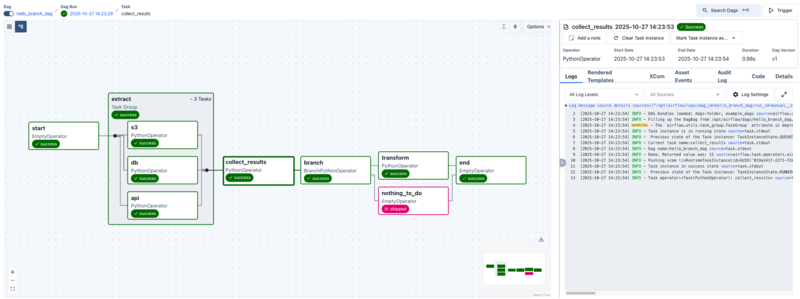
ただ、この構成だけでは Airflow の利点が伝わりにくいため、TaskGroup を使ってタスクをグルーピングし、条件に応じて分岐させる構成にしました。分岐は BranchPythonOperator で実装しましたが、分岐しなかった側が SKIPPED となるため、そのままだと合流時に実行が止まってしまいます。そこで、終端(end)をデフォルトの trigger_rule=all_success のままにせず、合流ノードの trigger_rule を緩和することで、正常に完了するように調整しました。
まとめ
定期的にデータを取得したり、モデルの学習・評価・レポート生成といった、「決まった順番で自動的に実行したい処理」を Airflow に任せるのはとても相性が良いと感じました。複雑な依存関係があっても、UI から状況を確認しながら安心してワークフローを回せるのが嬉しいポイントです。
ABEJAは、テクノロジーの社会実装に取り組んでいます。 技術はもちろん、技術をどのようにして社会やビジネスに組み込んでいくかを考えるのが好きな方は、下記採用ページからエントリーください! (新卒の方やインターンシップのエントリーもお待ちしております!)
{kind=link}