


こんにちは、CCCMKホールディングスAIエンジニアの三浦です。
もう11月です。寒くなってきて体調を崩しやすくなってきているので、体調管理には気を付けないと・・・と思っています!
“MCP“というワードを頻繁に聞くようになりました。私も以前調べたことがあって、その内容についてはこちらの記事にまとめています。
最近databricksが”managed MCP server“というMCP serverをBeta版で提供していることを知りました。これを利用するとdatabricksのworkspaceに構築したvector searchやgenie spaceにMCPでアクセスが出来るようになるようです。
また、MCPを利用する側(クライアント)ではLangChain MCP AdaptersというLangChainのライブラリを使ってみようと考えました。これを利用するとMCP serverで提供されている機能をLangChainのAgentで利用できるtool形式に簡単に変換することが可能です。
今回の記事はdatabricks上に構築したvector searchとgenie spaceをmanaged MCP server経由でLangChainから利用し、データ分析が出来るAgentを作る方法をご紹介します。
使用したデータセット
今回検証のために使用したデータセットはdatabricksの”samples”catalogに格納された、Bakehouseという架空のbakeryフランチャイズの売上やレビューなどのデータで構成されたものです。
このデータセットの中には”media_gold_reviews_chunked”というレビューテキストをvector searchに取り込めるようchunking済みのtableが含まれています。このtableからvector search indexを構築し、レビューを自然言語で検索出来るようにします。その他のtableはdatabricksのtext-to-sqlのAI”genie“で参照させるようにします。
どんなことが出来るAgent?
vector searchとgenieを接続したAgentは、たとえば”味について評判のいい店舗の売り上げは、全体と比べてよいですか?”といったような質問に対して実際のデータを分析して回答することが出来るようになります。
managed MCP serverを有効化する
databricksのmanaged MCP serverは現在Beta版となっており、利用するためにはPreviewsから”Managed MCP Servers”の項目を”On”にします。
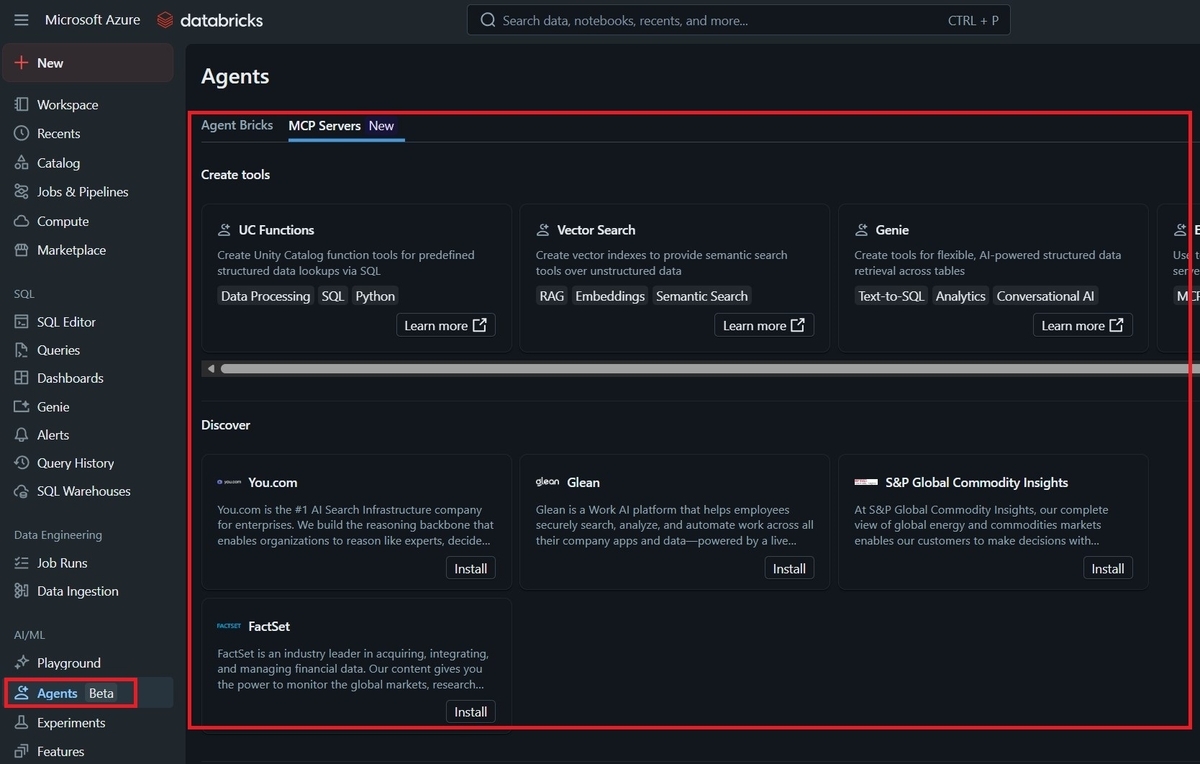
AI/MLの”Agents”のメニューから、利用可能なmanaged MCP serverの一覧を確認することが出来るようになります。
MCP serverのURL
vector search
vector searchのMCP serverは指定のschema配下のvector searchに対し自然言語のクエリから関連する情報を検索することが出来ます。
URLは以下の形式です。
https:///api/2.0/mcp/vector-search/{catalog}/{schema}
genie space
genie spaceのMCP serverは指定したgenie spaceに対し自然言語のクエリを渡し、データ分析を実行させることが出来ます。
URLは以下の形式です。
https:///api/2.0/mcp/genie/{genie_space_id}
vector searchの構築
次のような処理をdatabricksのnotebookで実行しました。
from databricks.vector_search.client import VectorSearchClient client = VectorSearchClient() client.create_endpoint( name="bakehouse_vectore_endpoint", endpoint_type="STANDARD" ) spark.sql(f""" CREATE OR REPLACE TABLE {catalog_name}.{schema_name}.media_gold_reviews_chunked TBLPROPERTIES (delta.enableChangeDataFeed = true) AS SELECT * FROM samples.bakehouse.media_gold_reviews_chunked """) index = client.create_delta_sync_index( endpoint_name="bakehouse_vectore_endpoint", source_table_name=f"{catalog_name}.{schema_name}.media_gold_reviews_chunked", index_name=f"{catalog_name}.{schema_name}.bakehouse_reviews", pipeline_type="TRIGGERED", primary_key="chunk_id", embedding_source_column="chunked_text", embedding_model_endpoint_name="databricks-gte-large-en" )
genie space
genie spaceは以下のようにbakehouseデータセットのtableを参照させました。
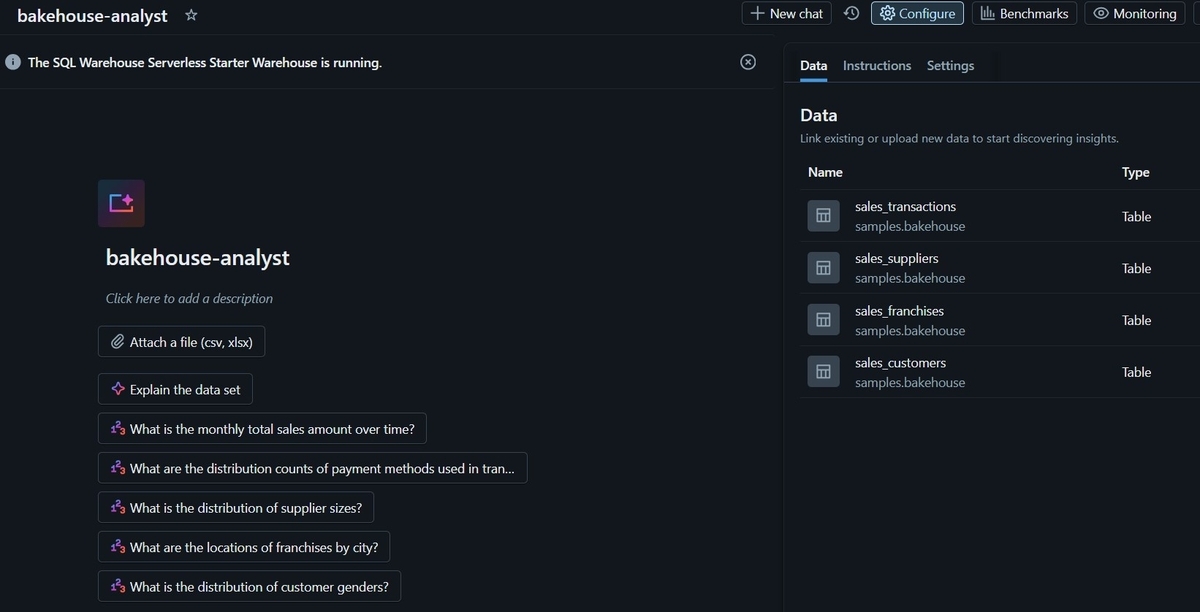
アクセスする際に必要になるgenie_space_idはこの画面の”Settings”タブから確認できます。
LangChain Agentの実装
ここからはLangChain Agentの実装です。必要なライブラリをインストールします。
typing-extensionsのバージョンが古く、エラーが発生したため、アップデートを行いました。
%pip install pip langchain langchain-openai langchain-mcp-adapters python-dotenv %pip install --upgrade typing-extensions dbutils.library.restartPython()
あとはAgentの実装ですが、MCPを使うことでとてもシンプルな実装でデータ分析Agentを構築することが出来ます。
from langchain.agents import create_agent from langchain_mcp_adapters.client import MultiServerMCPClient token = dbutils.notebook.entry_point.getDbutils().notebook().getContext().apiToken().get() ws_url = "https://" ws_url += spark.conf.get("spark.databricks.workspaceUrl") vector_search_url = f"{ws_url}/api/2.0/mcp/vector-search/{catalog}/{schema}" genie_url = f"{ws_url}/api/2.0/mcp/genie/{space_id}" review_search_setting = { "transport": "streamable_http", "url": vector_search_url, "headers":{ "Authorization": f"Bearer {token}", } } analyst_setting = { "transport": "streamable_http", "url": genie_url, "headers":{ "Authorization": f"Bearer {token}", } } client = MultiServerMCPClient( { "review_search": review_search_setting, "analyst": analyst_setting } ) tools = await client.get_tools() agent = create_agent( "azure_openai:gpt-4.1", tools, system_prompt="あなたはデータ分析を役割とするアシスタントです。与えられたツールを使ってユーザーの質問に回答してください。ツールを呼び出す際は英語でクエリを与え、最後の回答だけ日本語で生成してください。" )
このAgentを使って、たとえば次のような分析が可能になります。
await agent.ainvoke( { "messages": [ {"role": "user", "content": ""味に関する評判が良い店舗を探し、その売上が全体の売上の平均と比較してどのように違いがあるか教えてください。""} ] } )
vector searchとgenie spaceに複数回アクセスし、最終的に以下のような結果が出力されました。

いい感じです!
MCP serverを使うメリット
私はよくLangChainやLangGraphでAgentを作ることがあります。その中で特にAgentに渡すtoolの開発に時間がかかることが多いです。たとえばあるREST APIを実行するようなtoolを実装する時は
- REST APIの仕様を調べる
- REST APIを呼び出す処理を書く
- REST APIのレスポンスを解析する処理を書く
- REST APIを呼び出す処理をwrapしたtoolを実装する
- toolの説明情報を記述する
といった作業が必要になります。MCP serverを使うとこれらの作業が全てMCP server側で実装済みなので、Agentを作る側としてはAgentにどんな機能を搭載しようか、ということにだけ専念出来るようになります。
また、今回LangChaiでAgentを作りましたが、例えばDifyといったノーコードでAgentが構築できるシステムも増えてきました。DifyにもMCP serverを利用できる機能が搭載されているため、今回実装した内容をDifyでも実現することが可能だと思います。
まとめ
“MCP”と聞くとちょっとモヤモヤする印象がありましたが、自分で使ってみるとその便利さが身に染みて分かりました。また、今後私たちが開発したロジックなどをdatabricksのmanaged MCP serverで別のAgentに提供する、といったことも出来るんじゃないか、と可能性を感じました。
databricksだけでなくsnowflakeにもMCP serverがあるようなので、今度はそちらも調べてみたいと思いました。
{kind=link}