
目次
-
検索の未来が変わっている
-
実装に入る前の技術的な考慮事項
-
何をしたのか:構造化データの体系的な実装
-
エンティティ関係の重要性:@graphと@id
-
表現力と拡張性
-
@graphと@idのメリットまとめ
-
ページ別実装の詳細
-
企業ページ
-
募集詳細ページ
-
ストーリーページ
-
モニタリング
-
プラットフォーム別トラフィック分析
-
SEOの変化
-
今後期待される効果
-
最後に
検索の未来が変わっている
AIが新しい「入り口」になりつつある
いま、多くの人がAIアシスタントを使って情報を探すようになっています。
「おすすめの求人サービスを知りたい」と自然な言葉で質問したとき、AIは検索エンジンの順位ではなく構造的に整理されたデータをもとに情報を提示します。
そのため、どれだけ良いコンテンツがあってもページの構造が整っていなければAIが正しく理解できず、ユーザーに届かない可能性があります。
情報が「見つからない」リスクを防ぐために
AI検索が普及する今、「見つけられること」自体がブランド価値に直結します。
もしWantedlyの情報がAIに正しく認識されなければ、存在していても他社の情報に置き換えられてしまうリスクがあります。
この課題を解決するため、AI時代に最適化された情報構造の整備を進めてきました。
構造化データでAIに「理解される」サイトへ
このたびウォンテッドリーではマーケティングとエンジニアが連携し、重要ページに対して構造化データ(Schema.org)の実装を完了しました。
AIや検索エンジンがページの内容をより正確に理解できるように、以下のような構造を導入しています。
- JobPosting(募集ページ)
- Organization(企業ページ)
- Article(ストーリー)
それぞれのページタイプに合わせて最適なデータ構造を設計し、AIがウォンテッドリーの情報を正確に認識・提示できるようになりました。
これにより検索エンジンからの流入だけでなく、AIを経由した新しいトラフィック経路も期待できるようになります。
実装に入る前の技術的な考慮事項
1. 効率的な実装戦略
全社のすべてのページに手作業で JSON-LD を追加する方法では拡張性が低く、ページタイプごとの共通点も見えにくい状態でした。 より効率的に実装を進めるために以下の仕組みを検討・導入しました。
- バックエンドで動的に JSON-LD を生成する構造
- 再利用可能なヘルパー関数とモジュール化
- データモデルとの自動同期メカニズム
2. コンテンツ変更時の自動反映
ページコンテンツが変更されるたびに、構造化データが自動的に更新されるようになっています。
ページデータ(採用情報、企業情報、ストーリーなど)が変更されると対応する構造化データも自動的に更新され、手作業で JSON-LD を修正する必要がありません。
3. SEO 検証
実装後には以下の方法で検証しました。
何をしたのか:構造化データの体系的な実装
Schema.org 標準を活用してプラットフォームの主要ページに構造化データを JSON-LD 形式で実装しました。
構造化データを正しく実装することと共にドメイン全体でエンティティ間の関係を明確に表現することを重視しました。
エンティティ関係の重要性:@graphと@id
@graph とは?
JSON-LD で複数のエンティティ(Entity)を1つの統合コンテキスト下で定義できる文法です。
今回の実装において最も重要な技術的決定の1つは@graph文法と@idの使用です。これで構造化データを単なる「ページ内情報」ではなく、ドメイン全体のエンティティ関係までGoogle Search RobotとAIに明確に提示しています。
@graphを使用しない例
{
"@context": "https://schema.org",
"@type": "Organization",
"name": "Company A"
}
{
"@context": "https://schema.org",
"@type": "JobPosting",
"hiringOrganization": { "name": "Company A" }
}
@graphを使用した例
{
"@context": "https://schema.org",
"@graph": [
{ "@type": "Organization", "@id": "#org", "name": "Company A" },
{ "@type": "JobPosting", "hiringOrganization": { "@id": "#org" } }
]
}- すべてのエンティティが1つの@contextの下に定義される
- 「1セットの情報」としてまとめられたJSONが作成できる
-
- 人間が読みやすい情報はAIも読みやすい
表現力と拡張性
@graph文法を仕様すると1つのエンティティのタイプを定義する同時に、他のエンティティの下位タイプとしても定義することができます。
特にエンティティが増えて複雑になった場合、柔軟に拡張・組み合わせることができるメリットを持っています。
より複雑なケースで@graphを使用した例
{
"@context": "https://schema.org",
"@graph": [
{
"@type": "Organization",
"@id": "https://www.wantedly.com/#organization",
"name": "Wantedly",
"url": "https://www.wantedly.com/",
"sameAs": ["https://wantedlyinc.com", "https://www.facebook.com/wantedly"]
},
{
"@type": "WebSite",
"@id": "https://www.wantedly.com/#website",
"publisher": { "@id": "https://www.wantedly.com/#organization" }
},
{
"@type": "WebPage",
"@id": "https://www.wantedly.com/companies/wantedly#webpage",
"isPartOf": { "@id": "https://www.wantedly.com/#website" },
"publisher": { "@id": "https://www.wantedly.com/#organization" },
"mainEntity": { "@id": "https://www.wantedly.com/companies/wantedly#organization" }
},
{
"@type": "Organization",
"@id": "https://www.wantedly.com/companies/wantedly#organization",
"name": "Wantedly, Inc.",
"url": "https://www.wantedly.com/companies/wantedly"
}
]
}@graphと@idのメリットまとめ
- @graph
-
- すべてのエンティティが1つの@context下で定義される
- 人間もAIも「これらは 1 セットの関連情報」として認識
- @id
-
- @idで各エンティティを一意に識別
- 同じ@idはどこでも同じエンティティを意味する
- 重複定義を完全に排除
ページ別実装の詳細
企業ページ
https://www.wantedly.com/companies/wantedly
Schema 構造
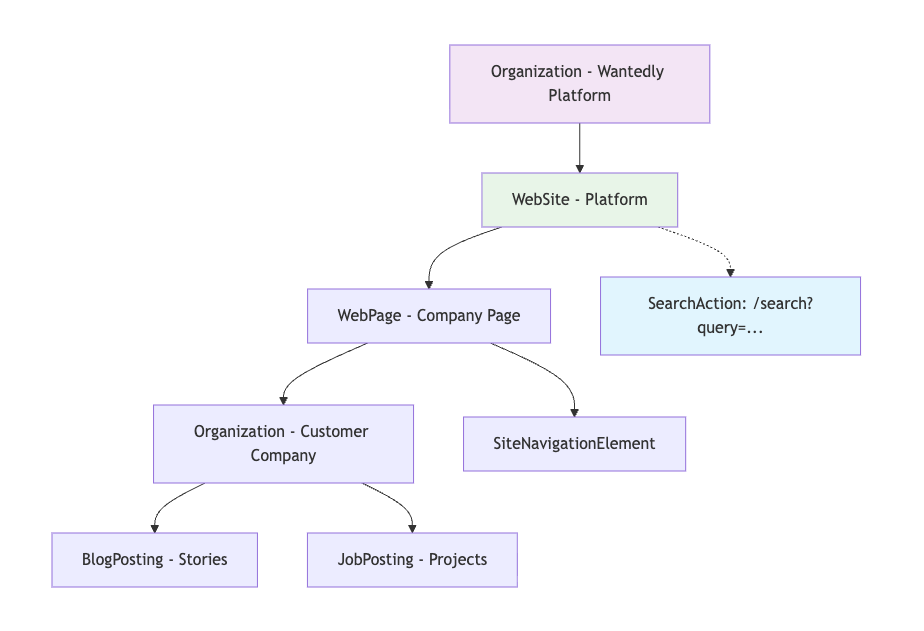
- Organization (Wantedlyプラットフォーム)
- WebSite (プラットフォーム全体)
- WebPage (企業詳細ページ)
- Organization (企業情報)
- ItemList – JobPosting (最大 3 件の採用情報)
- ItemList – BlogPosting (最大 3 件のストーリー)
- SiteNavigationElement (ナビゲーション)
- BreadcrumbList (パンくずリスト)
含まれる情報
- 企業情報
-
- 企業名、ロゴ (必須)
- 設立日、従業員数
- 企業紹介、スローガン
- 主要ソーシャルネットワークリンク
- 住所 (国、地域、市町村)
- 法務情報 (法人名など)
- 採用情報 (最大3件)
-
- 職務タイトル、説明
- 公開日
- 雇用形態、職種カテゴリ
- ストーリー (最大3件)
-
- タイトル、説明
- 公開日、更新日
- 著者、企業情報
- サムネイル画像
{
"@type": "Organization",
"@id": "https://www.wantedly.com/companies/example#organization",
"name": "Example Corp.",
"url": "https://www.wantedly.com/companies/example",
"logo": {
"@type": "ImageObject",
"url": "https://example.com/logo.png"
},
"foundingDate": "2010-09-01",
"numberOfEmployees": {
"@type": "QuantitativeValue",
"value": 120
},
"description": "ビジネスSNSを通じて、個人と企業をマッチング",
"slogan": "シゴトでココロオドル人を増やす",
"address": {
"@type": "PostalAddress",
"streetAddress": "東京都港区白金台5-12-7",
"addressRegion": "東京都",
"addressLocality": "港区",
"postalCode": "108-0071",
"addressCountry": "JP"
},
"sameAs": ["https://example.com", "https://www.facebook.com/example", "https://twitter.com/example"],
"areaServed": [
{ "@type": "Country", "name": "JP" },
{ "@type": "Country", "name": "SG" }
]
}AI が理解できる内容
「この企業はどのような企業か?」
→ Organizationのdescription、sloganで把握「最新の採用情報は?」
→ ItemListの最新3件のJobPostingで提示
「企業のストーリーは?」
→ BlogPosting ItemListで推奨
「企業の全体像」
→ @graphで プラットフォーム → WebSite → WebPage → Organization の関係性を認識
募集詳細ページ
https://www.wantedly.com/projects/1159802
Schema 構造
- Organization (Wantedlyプラットフォーム)
- WebSite (プラットフォーム全体)
- WebPage (募集詳細ページ)
- JobPosting (採用情報 – メインエンティティ)
- Organization (採用企業)
- BreadcrumbList (パンくずリスト)
含まれる詳細情報
- 採用情報 (必須フィールド)
-
- タイトル (title)
- 説明 (description)
- 公開日 (datePublished)
- 雇用形態 (employmentType)
- 採用企業 (hiringOrganization)
- 勤務地 (jobLocation)
- 採用情報 (選択フィールド)
-
- 職種カテゴリ (occupationalCategory)
- 募集終了日 (validThrough – 募集が終了している場合のみ)
- 採用情報画像 (image)
- ダイレクト応募可否 (directApply: true/false)
- 採用職に必要な経験 (記事の説明から抽出)
{
"@type": "JobPosting",
"title": "Senior Frontend Engineer",
"description": "We're seeking an experienced frontend engineer...",
"datePosted": "2024-08-26",
"employmentType": "FULL_TIME",
"hiringOrganization": {
"@type": "Organization",
"@id": "#company-org",
"name": "Wantedly Company"
},
"jobLocation": {
"@type": "Place",
"address": {
"@type": "PostalAddress",
"addressCountry": "JP",
"addressRegion": "東京都",
"addressLocality": "港区"
}
},
"occupationalCategory": "ソフトウェアエンジニア",
"validThrough": "2024-10-26",
"image": "https://example.com/job-image.jpg",
"url": "https://www.wantedly.com/projects/123",
"directApply": true
}AI が理解できる内容
「東京のフロントエンドエンジニア募集」
→ jobLocation.addressRegion + occupationalCategory でマッチング「3年以上経験のエンジニア」
→ description + occupationalCategory で検索
「まだ募集中の職務」
→ validThrough で募集期間を確認
「〇〇企業の採用情報」
→ hiringOrganization の @id で企業別フィルタリング
ストーリーページ
https://www.wantedly.com/companies/wantedly/post_articles/929480
Schema 構造
- Organization (Wantedlyプラットフォーム)
- WebSite (プラットフォーム)
- WebPage (ストーリーページ)
- BlogPosting (ブログポスト)
- BreadcrumbList (パンくずリスト)
含まれる情報
- headline (タイトル)
- description (説明、記事本文から抽出)
- datePublished (公開日)
- dateModified (更新日)
- author (企業 Organization)
- publisher (Wantedlyプラットフォーム Organization)
- image (記事画像)
- mainEntityOfPage (ページ URL)
{
"@type": "BlogPosting",
"headline": "採用ストーリー: 〇〇氏のキャリア転換記",
"description": "記事の要約",
"datePublished": "2024-08-26T10:00:00Z",
"dateModified": "2024-08-27T15:30:00Z",
"author": {
"@type": "Organization",
"@id": "企業 Organization の ID"
},
"publisher": {
"@type": "Organization",
"@id": "Wantedly プラットフォーム Organization"
},
"image": "https://example.com/story-image.jpg",
"mainEntityOfPage": {
"@type": "WebPage",
"@id": "https://www.wantedly.com/stories/123#webpage"
}
}AI が理解できる内容
「Wantedly の最新ニュース」
→ BlogPosting の datePublished で最新コンテンツを推奨「特定トピックの企業ストーリー」
→ headline、description ベースのセマンティック検索
「〇〇企業の成功事例」
→ author (Organization) で企業別フィルタリング
モニタリング
プラットフォーム別トラフィック分析
主要なAIプラットフォーム(ChatGPT、Perplexity、Claude 等)からの流入トラフィックを直接追跡します。GA4、HubSpotでリファラー(Referrer)情報に基づいて専用ダッシュボードを構築し、各AIプラットフォーム別のユーザー数と成長トレンドを監視しています。
リリース直後からAI経由のリードが大幅増加しています。
SEOの変化
SEOの変化はGoogle Search Consoleからモニタリングしています。
会社ページ(Organization)
リリースを起点に、表示順位が約30%改善しました。
クリック数そのものには顕著な変化は見られませんが、より関連性の高いユーザー層に検索結果が表示されている可能性が高まったと判断できます。平均検索順位は一定水準で安定傾向を示しており、ドメイン全体の評価が徐々に向上し検索エンジンからの信頼性が間接的に高まっていると考えられます。
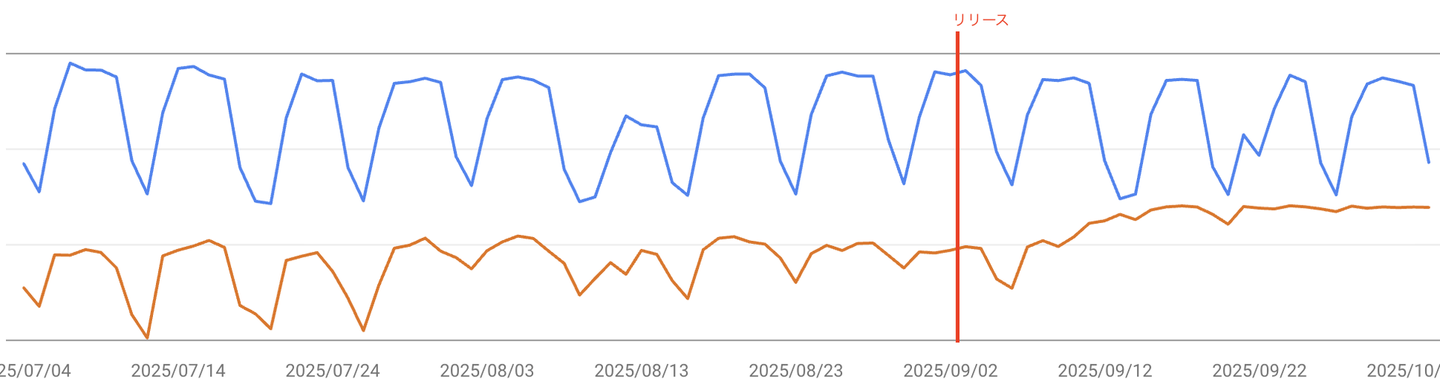
🟦:クリック数 🟧:平均表示順位
募集ページ(Job Posting)
リリースを起点に、表示順位が約30%改善しました。クリック数はリリース直後から徐々に上昇し、50%以上増加しました。
大きな急増ではないものの、安定した増加を維持しており検索結果内でより適切なユーザー層への露出が進んでいることがうかがえます。また、順位の変動幅も以前より小さく、平均順位が一定水準で安定しています。
なにより、Googleがこのページをエンティティとして正しく認識し、有効な求人情報が集計され始めたことから信頼性を持って評価していると考えられます。

🟦:クリック数 🟧:平均表示順位

🟩:有効な求人情報(JobPosting)数
ストーリーページ(Blog Post)
リリースを起点に、平均掲載順位は約40%の順位向上が見られました。一方でクリック数には大きな変化は見られず、全体的に安定した推移を維持しています。
検索結果での露出そのものが増えたわけではなく、Googleがページの構造や内容を正確に理解しより関連性の高い検索クエリに表示されるようになったことを示唆しています。
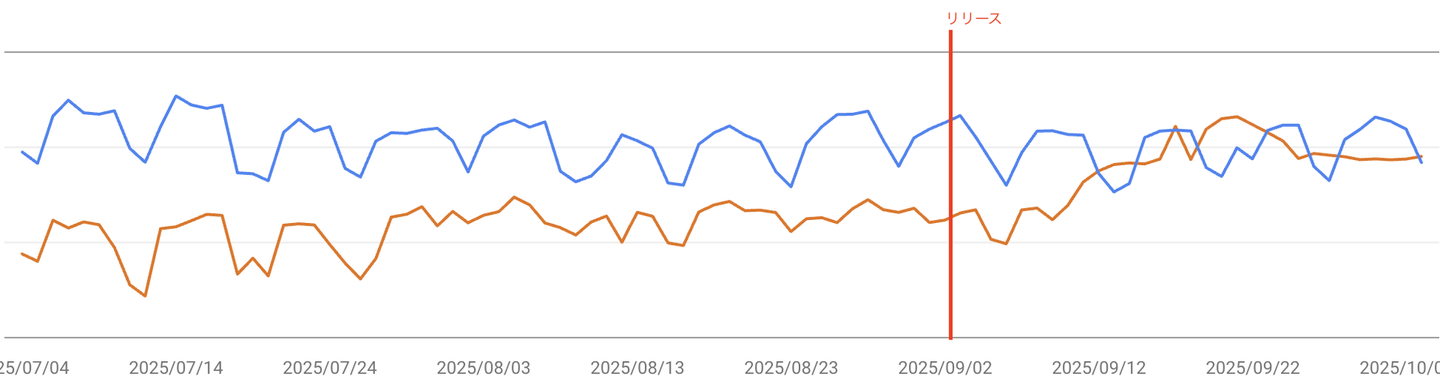
🟦:クリック数 🟧:平均表示順位
今後期待される効果
短期効果(3~6ヶ月)
- AI プラットフォーム上での Wantedly コンテンツの可視性向上
- AI 基盤の推奨で露出頻度が増加
- 構造化データに基づく新しいトラフィックチャネルの形成
中期効果(6~12ヶ月)
- AI 経由トラフィック成長トレンドの明確化
- 既存検索エンジントラフィックとの成果比較分析
- 構造化データ最適化を通じたマージン率の向上
長期効果(1年以上)
- AI 時代の検索環境での競争優位の確保
- 新しい情報発見チャネルとしてのポジション強化
- 検索エンジン依存度の低下とチャネル多様化
最後に
AI 時代の検索環境は急速に変わっています。コンテンツが新しい情報チャネルで正しく発見されるには今構造化データで最適化する必要があります。
これは単なる技術的な実装にとどまらず、未来の発見パスを構築する戦略としてサービスの成長を促進することを期待しています。
参考資料
{kind=link}