

ウォンテッドリーでバックエンドエンジニアをしている冨永(@kou_tominaga)です。本記事では、「ジョブが途中で止まり、ログにも例外が残らない」問題を原因特定から対策比較、実装まで順に解説します。一見まれな事象に見えますが、実際にはミドルウェアの設定値、デプロイやスケールインのタイミングなど、特定の運用条件が重なると再現しやすい問題でした。本記事ではその仕組みを明らかにし、同様の問題を防ぐための知見をまとめています。
前提
ウォンテッドリーでは、任意のタイミングでデプロイを実行できる オンデマンドデプロイ を採用しています。アプリケーションは Kubernetes 上で稼働しており、本記事はその環境で発生したジョブ中断の事象について解説します。
背景・問題の発見
長時間実行される Sidekiq ジョブが、ログに例外の記録もないまま唐突に停止する事象が確認されました。ジョブが途中で停止してもシステム的な不整合は発生しませんでしたが、処理を再開するにはブラウザから手動で再実行する必要があり、その間ユーザーに長い待ち時間が発生してしまうため、ユーザ体験への影響が大きい事象でした。

長時間実行されるジョブは、デプロイやスケールインによって中断されることがあります。よって、短時間のジョブ化が理想的ではありますが、ビジネス要件上、長時間処理が避けられないケースも存在します。
調査の結果、問題発生時のログに「Shutting down」という出力を確認しました。そして、デプロイとの相関を分析したところ、以下の条件が成立した場合にジョブが中断していることが分かりました。
- ジョブは長時間実行されるもの(実行に10分以上かかる)
- Kubernetes の terminationGracePeriodSeconds はデフォルトの 30 秒
- Sidekiq の timeout は 300 秒
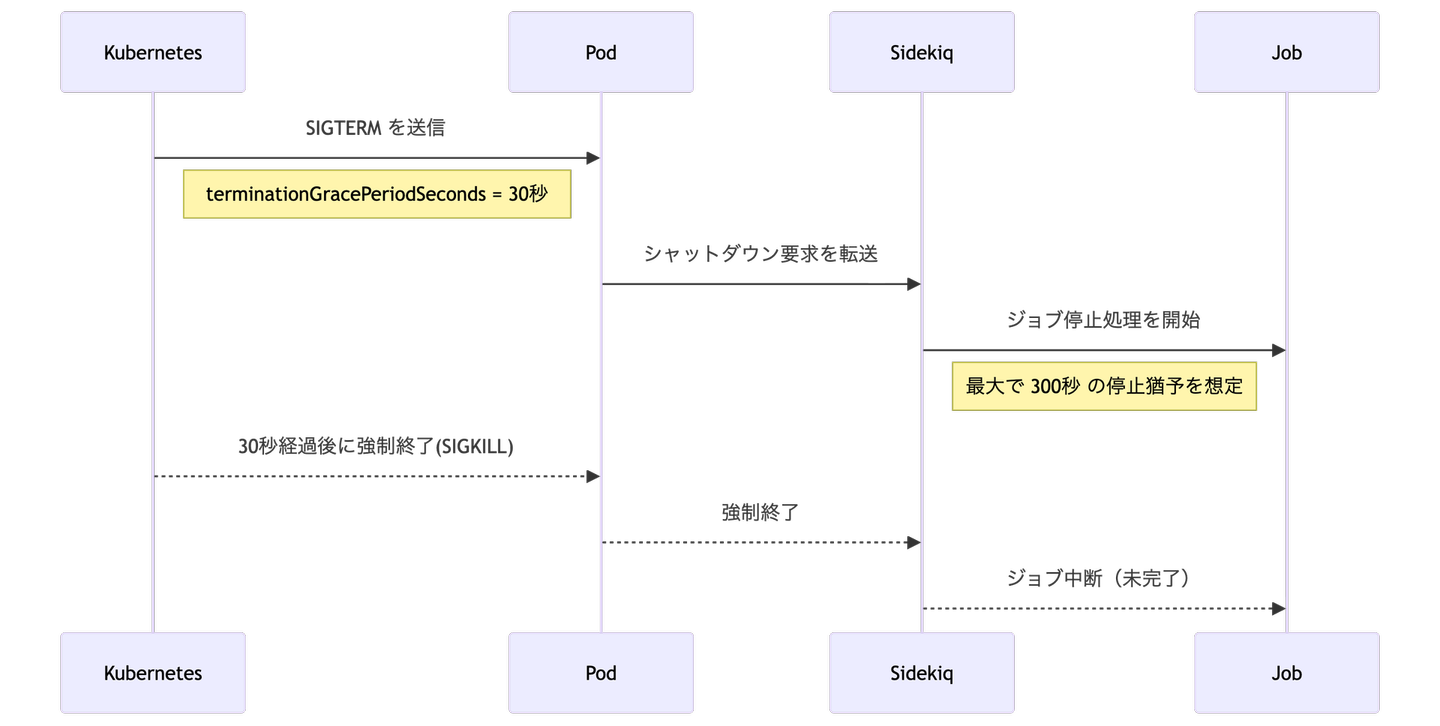
この構成では、 Pod が SIGTERM を受けた後、Kubernetes により 30 秒後に強制終了される可能性があります。一方、Sidekiq はジョブ停止に最大 300 秒の猶予を想定しているため、Pod の終了猶予が先に尽きてしまうケースが発生します。すなわち、「Pod の終了猶予時間」と「Sidekiq のジョブ停止猶予時間」の不整合が根本原因であり、この設計上のミスマッチによりジョブが中断していました。
解決策の検討
検討した選択肢と観点は以下の通りです。それぞれの対応で、以下の利点と懸念がありました。

検討の結果、「SIGTERM 受信時に進捗を保持し、自己再エンキューして安全に終了する」 方針を採用しました。この方法は、コストと影響範囲のバランスが最も良く、既存アーキテクチャを大きく変更せずに再実行の安全性を確保できる点が決め手でした。なお、Sidekiq のバージョンが十分に新しければ、Sidekiq::IterableJob を利用する選択肢もありました。

※★は対応コスト・影響範囲の相対的な大きさを示しています。★が多いほどコストや影響が大きいことを意味します。
実装の詳細
「SIGTERM を検知できるようにする」、「自己再エンキューによる再実行」の2ステップで対応しました。
1.SIGTERM を検知できるようにする
Sidekiq で SIGTERM を受け取ったことを検知できるようにします。以下、SidekiqStatus::ShuttingDown モジュールでは、 SHUTTING_DOWN というスレッドセーフなフラグを AtomicBoolean クラスで管理しています。on! メソッドでこのフラグをtrueに変更し、on?メソッドで現在の状態を確認できます。これにより、アプリケーションから「Sidekiq が停止処理中かどうか」を判定できます。
module SidekiqStatus
module ShuttingDown
SHUTTING_DOWN = Concurrent::AtomicBoolean.new(false) module_function
def on!
SHUTTING_DOWN.make_true
end
def on?
SHUTTING_DOWN.true?
end
end
end
次に、このフラグをSidekiqのライフサイクルイベントにフックさせます。configure_serverブロック内でquiet(ジョブの受付停止)およびshutdown(プロセス停止)イベントを検知し、そのタイミングでShuttingDown.on!を呼び出します。これにより、Sidekiqが停止シグナルを受け取った瞬間にSHUTTING_DOWNがtrueとなり、アプリ全体で安全に終了処理を制御できるようになります。
Sidekiq.configure_server do |config|
config.on(:quiet) do
SidekiqStatus::ShuttingDown.on!
end config.on(:shutdown) do
SidekiqStatus::ShuttingDown.on!
end
end
2.自己再エンキューによる再実行
ここからはジョブ側の実装です。先ほど追加したSidekiqStatus::ShuttingDown.on?を利用して、「今、Sidekiq はシャットダウン中か」を判定し、ジョブの中断と安全に再キューします。
class ExampleJob ApplicationJob
def perform(cursor: nil)
Example.where('id > ?', cursor || 0).order(:id).find_each do |example|
if SidekiqStatus::ShuttingDown.on?
return ExampleJob(cursor: example.id).perform_later
end
end
end
end結果と効果
ジョブの実行中にデプロイが行われても、自動的に再エンキューされることで処理が継続されるようになりました。結果として、オンデマンドデプロイと長時間実行されるジョブの両立が可能になり、クラスター全体のterminationGracePeriodSecondsを無理に引き延ばす必要もなくなりました。デプロイ速度や切り替え体験への影響を抑えながら、安定した運用が実現できています。
まとめ
ジョブ設計では、OS・コンテナランタイム・ジョブキューシステムなど、複数の実行環境から送られる 終了シグナル(例: SIGTERM)や、Kubernetesのgrace period(終了猶予時間)をまたいで処理を安全に継続できるかを考慮する必要があります。猶予内に完了できない場合は、再エンキューや状態保持を組み合わせることで、安全に停止と再開を制御できます。
今回の実装では、アプリケーション自身が「停止の合図を理解して動ける」ようにしたことで、インフラの設定を複雑化させずに安定性を高めることができました。長時間実行されるジョブを扱う環境では、SIGTERM 受信時の振る舞いを、デプロイ設計の一部として考えることをおすすめします。
元の記事を確認する
{kind=link}