
はじめに
MNTSQ はそのサービスの性質(「契約」の集約、一元管理、活用)上、セキュリティの維持と向上が至上命題です。よってセキュリティ改善において強いモチベーションが存在します。
今回の取り組み以前にも AWS ベストプラクティスに沿った AWS アカウントの管理や各種ログの収集は行われていましたが、収集済みログの活用やセキュリティ系の AWS 各サービス運用には改善の余地が多々ありました。今回ここにテコ入れし、現状に寄り添った運用ができるように改善することを目論みました。
ここでいう「現状に寄り添った」運用とは以下のようなことを指します。
- 少ない人員でも無理のない範囲で状況把握ができること
- 管理の手間がなるべく発生しないようなシンプルな構成であること
- 機微情報に対するアクセス状況を追跡したいなど、上記を鑑みてもなお守りたいセキュリティ要件を達成できるような仕組みが整備できること
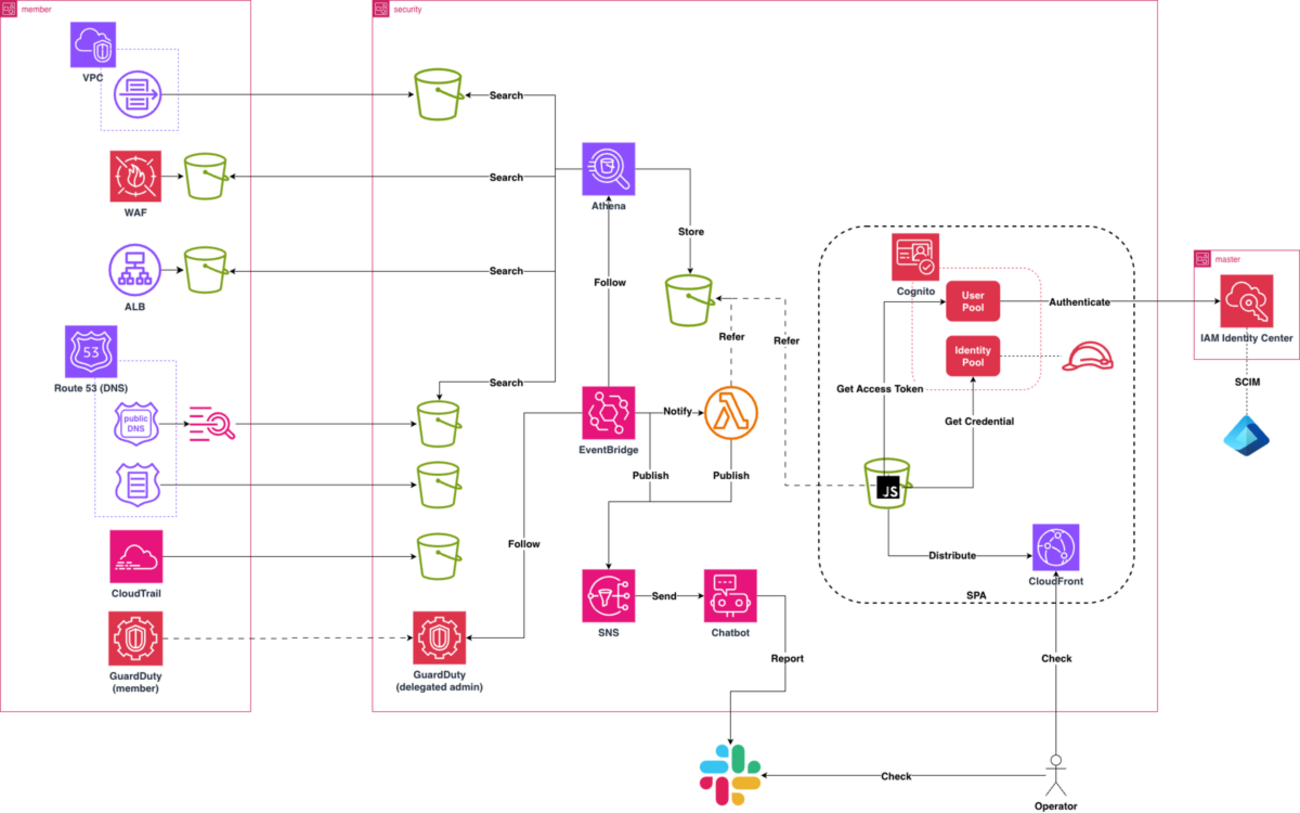
構成
おおむね以下のような構成をとっています。アイコンがいっぱい並んでいて「管理の手間がなるべく発生しない」構成なのかには議論の余地がありそうですが、AWS マネージドサービスを多用する構成につき、方針自体は問題ないと思います。

図中の AWS アカウントの区分は以下のようになります。
- member:実際にアプリケーションが動きワークロードを捌く環境(= AWS アカウント)
- security:セキュリティ関係の諸々を集約している AWS アカウント
- master:AWS Organizations 管理アカウント
- セキュリティ文脈では然程関係ないが上述 “security” な AWS アカウントとの関連で言及
構成図内の要素を大別すると以下のような部位に分けられるでしょう。
- ログ送出
- ログ保管
- GuardDuty 関係*1
- 分析
- 結果確認
以後それぞれについて解説します。
ログ送出

分析の項で別途詳述しますが、基本的には S3 バケットにログを置き、それを Athena によって検索 / 分析するような手法をとっています。つまり収集対象としたいログは S3 に置く必要があります。
標準で保存先を S3 に指定可能なサービスであれば話は簡単ですが、一部そうでないものもあります。上記構成図でいえば Route 53 公開 DNS クエリログが該当しました。こちらについての取り組みは拙稿の以下を参照ください。
tech.mntsq.co.jp
ログ保管

S3 バケットにログを置くようにさえ出来れば IAM ポリシ / S3 バケットポリシで定義される権限調整を頑張る前提で Athena から扱えるようになります。Athena と S3 バケットとは同一の AWS アカウントにあってもよく、また別個であっても構いません。とはいえ管理の手間や認知負荷などを考えればどちらか一方(= 同一アカウントに置くか別個のアカウントに置くか)に運用方針を寄せるのがベターでしょう。
弊社では現状を鑑みて無理に運用方針を統一させるのは止し、以下のように2つを並立させるようにしました。
- 既に長年にわたりログが蓄積されており、過去ログへアクセスできることが運用上でメリットになるもの
- Athena / S3 とで別アカウントに置くことを許容
- 新規にログ取得を開始したもの
- Athena / S3 それぞれ同一 AWS アカウントで取扱
前述のとおりセキュリティ関係の諸々は単一 AWS アカウント (security) で管理しており、この文脈において Athena はセキュリティ用 AWS アカウントで管理されます。
Athena と同一の AWS アカウントに置かれる S3 バケットは security に、別個の AWS アカウントに置かれる場合は member に、それぞれ存在することになります。
GuardDuty 関係
ここは至極単純で、GuardDuty をほぼ吊るしで使うのみです。本番環境用の AWS アカウントでは S3 向けの malware protection*2 も有効にしています。前述のとおりセキュリティ用 AWS アカウントを delegated admin*3に設定し、他の AWS アカウントをすべて member 扱いにします。member / delegated admin 問わず、すべての GuardDuty 検出内容 (finding) はセキュリティ用 AWS アカウントの GuardDuty で管理します。
分析

各ログ別にデータベースを、環境別にテーブルを、それぞれ Athena 上に選択します。データベースにあわせて workgroup も分けるようにしました。これは以下効果を狙ってのものになります。
- Athena ログ検索結果を活用するにあたり、結果の格納先をログの種類別に分けたかった。これを手間なくやる*4には workgroup 単位で保存先を指定する必要があった
- workgroup を定義することで Athena クエリ実行状況を EventBridge によって追跡することができ、後処理をイベント駆動的に実施できるようになる利点があった*5
Athena によるログ分析は週次での定期実行とし、ログ分析用 Athena クエリを名前付きクエリとして整備したうえで Lambda から当該クエリを呼び出すようにしています。
名前付きクエリではなく生のクエリを使うことで EventBridge スケジューラ*6 を使えるメリットがあるのですが、今回は EventBridge イベント(cron 記法によるスケジュール実行)+ Lambda 関数による実行の仕組みを整備しています。
これは定期実行したクエリ内容を適宜改変して詳細なログ調査を行いたい状況も多々あり、この改変に用いるクエリの元ネタを割合簡単に扱えるよう整備するには、名前付きクエリとして管理するのがベターと思われた為です。
結果確認

ログの内容や分析結果、およびそれらからどういった情報を得たいかによって、Athena クエリ結果の取り扱い方が変わります。弊社ではおおむね以下のような分類ができました。
- ログ検索結果としてごく少量の情報が得られ、そこから直ちにネクストアクションが決められるもの
- ログ検索結果から得られる情報が量的にそれなりの規模になってしまうものの、結果を踏まえてネクストアクションが決められるもの
- ログ検索結果から得られる情報が量的にそれなりの規模になってしまい、かつネクストアクションが決めづらいもの
各結果を実際にどう取り扱っているかについては後述しますが、上記3分類において、以下のような取り扱い方を整備することにしました。項番は前項3点にそれぞれ対応します。
- 検索結果とあわせて対応すべき内容を示した手順とを含めて Slack に流し、通知された結果をみて適宜対処
1.と同様- 結果確認用のアプリケーションを整備し、傾向の変化を観察する。異常が見られた場合は都度対処
要するに何をすればよいかが明確なものは通知して対処し、何をすべきか悩むものについては傾向をみるためのお膳立てを整える、といった指針になります。
なお 3. で示した結果確認用のアプリケーションは S3 にコンテンツを置き CloudFront で配信し Cognito で認証認可を行う SPA を用意し、これに Athena クエリ結果を浚わせて可視化するといった体制を組んでいます。このあたりの裏側については拙稿以下を参照ください*7。
実際の運用
ひとまずここまでで各種ログを取り扱うまでの仕組みについては解説できました。ここからは得られたものをどう運用しているかについて解説します。主に2つの区分の運用があります。
- 分析系
- 行動系
- 機微情報を収容する S3 バケット操作状況調査
- Redash 操作状況調査
- GuardDuty 検知内容調査
分析系
Route 53 クエリログ / VPC フローログ / WAF ブロックログを所定の方針で Athena によって週次で調査し、その結果を観察したうえで適当なアクションをとります。これら分析系の運用は前掲の
という3分類においては 2. と 3. に該当します。2025年10月現在、各ログはそれぞれ以下のような指針 / 手段でもって分析結果を取り扱うようにしています。
| 種類 | 方針 | 取り扱い方の分類 (前項 1., 2., 3.) |
運用方法 |
|---|---|---|---|
| Route 53 公開 DNS クエリログ調査 | NXDOMAIN ログの傾向観察*8 | 3. |
集計結果を自前の SPA で捌き観察 |
| Route 53 リゾルバクエリログ調査 | 継続して通信実績のあるドメイン宛以外に VPC 内からインターネットへ出るリクエストが無いか確認 | 2. |
未知ドメインがあれば詳細を確認し、既知ドメインはアクセス許可リスト*9 に追加 |
| VPC フローログ調査 | VPC 内からインターネットへ出る際のアクセス先に不審なものがないかを AS のレベルで確認 | 3. |
集計結果を自前の SPA で捌き観察 |
| WAF ブロックログ調査 | ブロック状況に変動が無いかを傾向観察*10 | 3. |
集計結果を自前の SPA で捌き観察 |
Route 53 クエリログについては 拙稿 も参照ください。本稿二度目の参照につきリンクテキストにて失礼します。
また SPA をつかった調査をしている事例は実際の風景をお見せできればよかったのですが、マスクすべき箇所があまりに多く、有益なものを提示できなさそうだったので、泣く泣く省略します。
行動系
ログ調査結果から直ちにアクションがとれるもの(つまり前掲の分類でいう 1.)がここに該当します。なお GuardDuty についてはログ云々の取り扱いではなく、GuardDuty が finding を上げたタイミングがアクションをとるトリガとなります。以下のような指針 / 手段になります。
| 種類 | 方針 | 運用方法 |
|---|---|---|
| 機微情報を収容する S3 バケット操作状況調査 | 特定の S3 バケットを対象に CloudTrail にて data event*11 を収集し、この結果として操作が認められた場合に背景などを確認 | 週次で前週分の操作ログを棚卸しし、操作対象者を特定の上で背景を非同期で確認*12 |
| Redash 操作状況調査 | Redash ログイン時ログおよび Redash クエリ実行ログを収集の上、勤務時間帯ではないタイミングでの操作が無いかを確認 | 週次で前週分の操作ログを棚卸しし、操作対象者を特定の上で背景を非同期で確認 |
| GuardDuty 検知内容調査 | GuardDuty 検知事項を素直に調査する | GuardDuty がなにがしかを検知したタイミングで調査タスクとして GitHub issue が作成され、issue ベースで内容を調査*13 |
Redash ログに関しては以下をもとにした内容を使い収集 / 運用しています。
tech.mntsq.co.jp
おわりに
弊社における AWS 各種ログの集約と活用、およびそれらを踏まえたセキュリティ系改善の取り組みについて解説しました。半年程度でここまでやったのだなと思う向きもありますし、まだまだやれた乃至やれることもあるよなとも感じています。
もちろんここまでに解説した内容については様々な改善余地があり、また現時点でも着手出来ていない施策が数多くあります。たとえば傾向観察が主体となっている取り組みについては掴んだ傾向を踏まえて具体的なアクションをとってゆく必要があり、GuardDuty / CloudTrail 以外にもこの種の用途では有効な AWS のセキュリティ関連サービスがあるはずです。よりよい組み合わせを模索し、今後もセキュリティ方面の最適化に取り組んでゆきたいと考えています。
記事中で扱った取り組みにおいて、特に何らかの制限を課す方向の取り組みはしていない向きに気付かれた方がいらっしゃるかもしれません。これは制約を課すセキュリティを目的とするものではなく、発生している事実を正確かつ適切なタイミングで把握するという方面に重きを置いている面があるためです。予防的統制のための取り組みであると言ってもよいかなと思います。
AWS サービスの各種ログの活用やセキュリティ施策の取っ掛りとして、本稿が何らかのお役に立てば幸いです。
MNTSQ 株式会社 SRE 秋本
{kind=link}