


こちらはLayerX AI エージェントブログリレー34日目の記事です。
こんにちは、CEO室でAI Agent開発のPdMをやっているKenta Watanabeです。
先日の記事に続いてeval関連の話題になります。
AIエージェントやLLMを使ったサービス開発をされている方は日々何かしらの環境でevalsを作成されているのではないかと思います。LangSmithやLangfuse, OpikやPromptfooなどLLMのtracingやevaluationを行うことのできるサービスはたくさんあり弊社でもLangfuseを活用しています。また、OpenAIはtracing/evaluationとも自社プラットフォームで行うことができ、Agents SDKを利用している場合はより簡単にこれらの環境を利用することもできます。
これらの基盤はevaluationとtracing, promptの連携や可視化、Web画面での実行など豊富な機能がありとても便利で、実サービスにてLLMを活用する場合にまず最初に導入されている方も多いのではないかと思います。一方で、evalsとは本来「ある入力をもとに実行したLLMコールの結果(又はそれを加工した値)と期待される値(又はそれを加工した値)」を比較する、従来のソフトウェア開発でいうテストのようなシンプルな活動であるにも関わらず、外部の基盤を構築したり実行の度に外部サービス(あるいは自社ホスティングしている基盤)へ接続するのもやや重厚に感じます。また、evalsはpromptの修正やLLMコールに関連するソースコードの修正とセットで必要になるため、ソースコードでの管理やCIでの確認ができると良さそうに思えますが、外部基盤の中のdatasetがSSoTとなり外部基盤での実行が前提となる構成との相性の悪さも感じます(ワークアラウンドはあると思います)。
このようなことを考えておりサービスやOpen Sourceの実装を調べていたところEvaliteというOpenSourceのProjectを見つけ触ってみたので、利用の流れや使い心地を簡単に解説したいと思います。
Evalite(github)はTypeScriptで書かれたevals実行ツールになります。
TypeScriptのプロジェクトにてpnpm add -D evalite vitestでvitestと共にインストール後、下記のようなevalスクリプトを作成しpnpm evalite serveでevaluationを実行することができます。vitestはTypeScriptで高速に動作するtestフレームワークで、evaliteの実行基盤として利用されています。
import { evalite, createScorer } from "evalite"; import { google } from "@ai-sdk/google"; import { generateText } from "ai"; evalite("PositiveNegativeEval", { data: [{ input: "今日はいい天気だなぁ", expected: "1" }], task: async (input) => { const result = await generateText({ model: google("gemini-2.5-flash"), prompt: `与えられた文章のポジネガを判定してください: ${input}\nポジティブなときは1を、ネガティブなときは0を返してください`, }); return result.text; }, scorers: [createScorer({ name: "PositiveNegativeCheck", scorer: async ({ output, expected }) => { return output === expected ? 1 : 0; }, })], });
中身はとてもシンプルでデータセットと実行タスクの中身、スコアリングロジックの3点を設定する形になります。これはdeterministicなシンプルなロジックを指定していますが、scorersの中身を書き換えればLLM as judgeを使うこともできます(Production向けのアプリケーションの評価であまり利用することはないと思いますがautoevalsなどの事前定義されたJudgerを使うこともできます)。
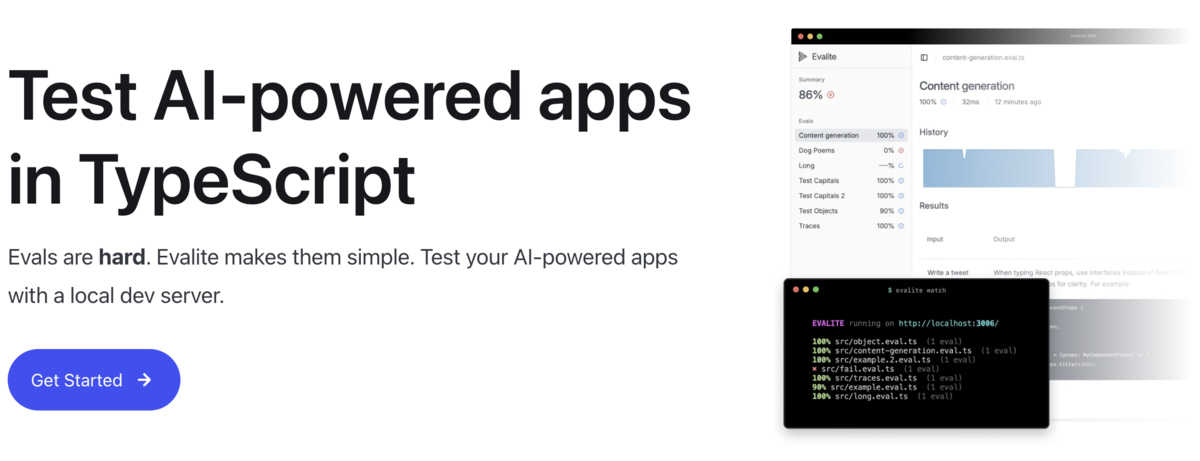
実行すると下記のようにterminal上で簡易的な結果を確認できると共にlocalhost:3006にてサーバが立ち上がりブラウザでリッチな画面でも結果を確認することができます。


ウェブ画面上では単発の評価の結果だけでなく、これまでの実行結果の推移や各データセットアイテムに対するIN/OUTの詳細などを確認することができます。データはSQLiteでローカルファイルに保存されるため、このような一通りの評価プロセスをとても簡易的なセットアップで行うことができます。
かなり簡易的な環境設定・実行環境でevaluationを行えることを確認しましたが、他にも様々な設定を行うことができます。local環境での実行のため、任意のLLMやOpen SourceのLLMを自由に実行できますし、reportTraceという関数を使うことでtraceデータもevaluationとセットで保存しウェブ画面で確認することができます。
簡単にEvaliteの利用の流れを説明しました。一方で実際のAI Agentの開発においては、LLMコールにおける出力を実際の入力データの傾向や失敗の傾向をモニタリングしながら、徐々に意図している出力にアラインしていくsteering作業を大量に行っていくことになります。ただこの作業を行う中で以下のような課題が出てくるのではないかと思います。
- 1つのLLMコールが重たいので、開発中のプロダクトで実行しながら確認していると時間がかかる
- evalsのデータを作成したが、全データをprompt修正の度に実行していると時間がかかるので、今改善しているpromptが特に影響する部分を集中的に実行して、まとめてから全体への副作用を確認したい
- 複数のモデルやPromptを切り替えた時の精度を比較したい
- LLM as Judge側のPromptを修正したいが副作用が怖い
Evaliteではこれらの要求に応えられる機能が用意されており、快適なevaluation作業を進めることができます。
evalite("PositiveNegativeEval", {})とすべきところでevalite.skip("PositiveNegativeEval", {})のように記載することで一部のevaluationのみを実行することができます。また、実行するケースの中のinputデータに対して
evalite("My Eval", { data: () => [ { input: "test1", expected: "output1" }, { input: "test2", expected: "output2", only: true }, ], task: async (input) => { }, });
のようにonly: trueをつけることでこれがついたケースのみを実行することができます。
configurationの中で各ケースを何回実行するかを指定できるため、これらの機能を組み合わせることで「このエッジケースに対するprompt調整を10並列で回して高速にfailureパターンを確認・prompt修正し、完了したら改めてevals全体を回して副作用含めて全体影響を確認する」といった作業を効率よく行うことができます。
特にAIエージェントの開発をすんなり行っている場合、実際のプロダクトにて入力を与えて結果を確認するといった開発フローになりがちだと思いますが、LLMは確率的な動作をするため並列に同じ入力を複数回与えて色々なパターンを確認することで一気に開発スピードを早めることができます。
Variant Comparisonを用いることで、複数のモデルやPromptの精度比較も簡単に行うことができます。Scorersも複数設定して横比較しやすいため、Judger側のLLMの修正時は元のJudgerを残したまま新しいJudgerを作成し、一定期間両方残したまま副作用を確認するといったこともカジュアルに行えます。
さて、ここまでEvaliteの使い方とメリットを見てきましたが、EvaliteはSource Codeがevalsデータセットの大元になる設計で作られているため、GitHubを中心とした開発との相性が非常によくなります。Evalsのデータセット自体がSource Codeになるため、Prompt変更やAgentの構成変更とEvalsの変更を同じPRに載せてレビューを行うことを作業の前提とすることが容易です。さらにevalsの結果をstaticなHTMLにexportすることもできるため、CI上で実行させてレビュー時に結果を確認することもできます。ともすればTest以上にプロダクトへの影響や副作用が大きいAgent開発において、このような構成を取ることを前提に作られているのはとても良いのではないかと思います。
いかがでしたか?これまでEvaliteの良い部分だけを紹介してきましたが、実際にはtraceの可視化が非常にシンプルなものだけであったり、TypeScriptでよく使われており使い方に慣れているユーザも多いvitestのフレキシブルな実行スタイルをそのまま使えなかったりとこれからの開発に期待したいところはありますが、SaaSでの利用や各種セットアップ・運用の必要なTrace/Observeツール以外の選択肢として一定の有用性はあるのではないかと思っており、個人的にはこれからの開発に期待しています。
LayerXではLLMが前提になった世界での経済活動のデジタル化や摩擦の解消へ真正面から向き合うべく、LLMを活用したAI Agentの開発に真正面から向き合って取り組んでいます。今回紹介したような内容以外にも、AI Agentを開発する中でevaluationに関する課題を、プロダクショングレードのプロダクトを作る過程で1つずつ向き合いながら対応しています。
- evaluationはどの粒度で行うべきか?
- どのタイミングでどれくらいのevalsを用意しながら開発すべきか?
- evalsの自動化は行うべきか?どの作業で行うべきか?
- Claude Codeの開発は結構Vibeに評価してる部分もあるってきいたけど実際どうなん?
- 顧客によってデータが違うのでevalできる量の限界あるんじゃない?
そして、これらの課題に向き合う仲間を全力で募集しています!。少しでもこれらのLLM活用に興味のある方がいればぜひ一度お話をさせてください!また、LLMやAIに興味はあってCoding Agentやモック制作にAIは使っているけど、作る側での知識や経験がないEngineerやPdMの方も多いのではないかと思いますが、そういった方でもぜひお声がけください。AI関連の技術は進歩が急激ではありますが、そもそもまだほとんど経験者のいない新しい技術です。AIへの圧倒的な好奇心を持って試行錯誤ができる方であればAIを利用したプロダクトの開発経験は問いません。
ここまでの速度で技術が発展し、全く新たなプロダクトを生み出せる機会というのは10年に一度しかないと思います。この激動の時代をまたとない機会と捉えて集中しつつも、全力で楽しんでLLMに向き合える方をお待ちしています!
また、この記事はLayerXエージェントブログリレー34日目の記事です。
明日以降も毎日AI Agentに関する記事が公開されますので、LayerX Tech公式Xアカウントか私のXをフォローしてチェックいただければ幸いです!
{kind=link}