

はじめに
弊社が採用しているDB設計は、テナントごとに独立したスキーマを持つ「スキーマ分離」 のデータ構造に基づいています。このアーキテクチャは、高いデータ分離性とセキュリティを確保できる一方で、「スキーマ数の増加に伴ってパフォーマンスが劣化する」という性質が指摘されます。
サービスのスケールにおいてこの「性能劣化」が、いつ、どのように顕在化するのかは、設計上の大きな課題でした。この漠然としたリスクを定量的に評価し、将来的な「行分離」アーキテクチャへの移行の是非を判断することを目的に、負荷試験を実施しました。
本記事では、この試験で明らかになった、スキーマ分離アーキテクチャの抱える本質的なボトルネックを共有させていただきます。
※ MySQLでは”SCHEMA”よりも”DATABASE”という呼び方が一般的ですが、本記事では宗教上の理由により”スキーマ“と表記させていただきます
スキーマ分離と行分離
マルチテナントのデータベース設計において、代表的なデータ分離方式は「スキーマ分離」と「行分離」の2つです。弊社が現在採用しているのは「スキーマ分離」方式です。
それぞれの分離方式の特性を比較します。

弊社サービスは、元々シングルテナントで運用していた過去があり、スキーマ分離を選択しました。しかし、マルチテナントのリアーキテクトが完了し、事業がスケールするフェーズに入ったことにより、スキーマ分離の抱えるリスクを無視できなくなってしまいました。
目的と結論
目的
記事冒頭に記載した通り、現在のスキーマ分離データ構造が、サービスのスケールに伴い、どの段階で性能上の限界を迎えるのかを明確にし、アーキテクチャ移行の要否と期限を定めることが目的です。
結論のサマリ
-
性能劣化の要因は、クエリの絶対量よりもスキーマ数の増加にある
-
弊社ケースでは600テナント数を超えると、データディクショナリへのメタデータアクセスへの待機時間が顕著になり、これが性能劣化の支配的な要因となる
試験内容
試験環境とツール
試験環境の構成は基本的にRDS+EC2のみです。
- 試験対象のRDS (Aurora MySQL)
- 負荷をかけるEC2インスタンス
- OSは不問 (今回はUbuntuを使用)
- スペックはかけたい負荷の関係でc6gn.2xlargeから最終的にc6gn.8xlargeまで上げた
また、負荷試験にはqubeというオープンソースのツールを使用しました。このツールは一つのスキーマにしか負荷をかけられないため、これを複数スキーマに対して並列実行し、出力されたレポートを集計するbashスクリプトを、以前記事にしたDevinに作成してもらいました。
集計レポートはこんな感じ
{ "StartedAt": "2025-09-25T07:30:32.531620003Z", "FinishedAt": "2025-09-25T08:42:16.475152837Z", "ElapsedTime": 1800, "ParallelCount": 24, "TargetSchemaCount": 150, "QueryCount": 44652323, "ErrorQueryCount": 0, "AvgQPS": 847.79, "TotalQPS": 24806.84, "Duration": { "P50": "304.22µs", "P75": "364.25µs", "P95": "639.14µs", "P99": "886.44µs", "P999": "1345.26µs", "Avg": "343.97µs", "Max": "37678.64000µs", "Min": "141.706µs", "TotalSamples": 44652323 } }
負荷の設計
本番環境でのクエリ傾向の分析
MySQLではperformance_schema.events_statements_summary_by_digestというテーブルで、クエリを正規化して集計した情報を見ることができます。
(例えばWHERE id = 120をWHERE id = *として、値部分が異なるクエリも同じクエリとみなします)弊社サービスの場合は、本番環境のクエリの80%以上が、上位11種類のクエリで占められていました。この11種類のクエリ比率を崩さないように、具体的な値を入れてSQL文を10000個程作成し、qubeで実行可能なjsonlファイルを作成しました。(この作業もDevinで行いました。生成AIの進化に感謝です)
なお、SQLをどの程度用意すべきかはケースバイケースです。今回のケースでは1スキーマに数百QPSの負荷を5秒程度かけて次のスキーマに負荷をかけるということを行うので、10000種類程度用意すれば同じSQLが何度も流れることはないだろうと判断しました。MySQL8以降はクエリキャッシュの概念がないので、ここまでシビアになる必要はなかったかもしれませんが、キャッシュが効く環境だと、この点も考慮しないと意味のない負荷試験になってしまうので注意しましょう。
QPSの測定
クエリ傾向とは別に、本番環境でのQPS (Query Per Second)を測定しました。SHOW GLOBAL STATUS LIKE 'Questions'というSQLで、MySQLが起動してから受け付けたクエリの総数がわかります。サービスがよく利用される時間帯でこの値の増分を記録し、1秒あたりに直すことでQPSを見積もることができます。時期・曜日など、サービスの利用のされ方が異なる複数の日の結果を平均するのが好ましいでしょう。
弊社サービスでは約3200QPS程度でした。
進め方
スキーマ数に比例して負荷を増やしていき、目標QPSを達成できない点を見極めます。
- スキーマ数: 150 → 300 → 600 → 1200と増やしていき、限界点が見えたらその間の設定も追加で検証する
- QPS: 3,200 → 6,400 → 12,800 → 25,600と増やしていく(スキーマ数=テナント数にQPSが比例するという厳しめの条件)
試験ツールは、指定の数だけスレッドを立ち上げ、各スレッドは指定したローテーションの時間だけスキーマに負荷をかけ、終わったら次のスキーマに負荷をかけに行きます。ローテーションごとにレポートを保存し、全実行が終わり次第全てのレポートを集計した統合レポートを出力します。今回の試験では、スキーマごとに5秒程度の負荷をかけてローテーションし、全体で30分ほど測定を行いました。
# 4並列の場合 Thread1: schema_1 → schema_5 → …. Thread2: schema_2 → schema_6 → …. Thread3: schema_3 → schema_7 → …. Thread4: schema_4 → schema_8 → ….
試験結果
スキーマ分離のボトルネック
弊社のケースだと、600スキーマを超えたあたりで急激な性能劣化が見られました。縦軸が対数目盛りである点に注意してください(遅延は1目盛り増えると10倍になる)

800スキーマ以上では目標QPSまで負荷を上げることができなかったので、600スキーマ時点の負荷設定(クライアント側で24並列, 合計12000QPSをかける設定)で固定してデータを取りました。クライアント側の設定を固定しても、達成できるQPSは800テナント以降では顕著に低下していきました。
また、1200スキーマの負荷をかけていた時間帯のパフォーマンスインサイトを見て、遅延の原因を考察してみます。簡単に見方を説明すると、灰色の破線がCPUのキャパシティで、これを超えているとよろしくない状態であると言えます。問題なく稼働しているDBでは、破線よりも下のラインに収まっているはずです。

このグラフを見ると、dict_sys_mutexやparser_mutexなどの待機時間が支配的になっていることがわかります。これは、MySQL8.0以降では、データディクショナリテーブルがmysql.ibdという単一の InnoDB テーブルスペースに保存される仕様に起因していることが考えられます。
dict_sys_mutexは、データディクショナリへのアクセスが競合状態となった際に発生する待機イベントで、例えばオープンテーブルキャッシュに載ってないテーブルにアクセスする場合などにデータディクショナリへのアクセスが必要になります。テーブル数の増加に伴い、この際に競合が発生しやすくなります。
parser_mutexは、クエリのパースの際にテーブル・カラムなどの情報をデータディクショナリから取得する際の競合イベントで、やはりこちらもテーブル数の増加に伴い顕著になります。
スキーマ数を固定して負荷をあげてみる
データディクショナリへのメタデータアクセスが性能劣化の原因になるならば、スキーマ数(=メタデータのサイズ)を固定すれば、より大きな負荷を捌けるはずです。スキーマ数を600に固定し、当初予定していた1200スキーマ相当の負荷(24000QPS)を捌けるかの測定も行ってみました。
結果は以下のとおりです。今度は縦軸は線形目盛りです。
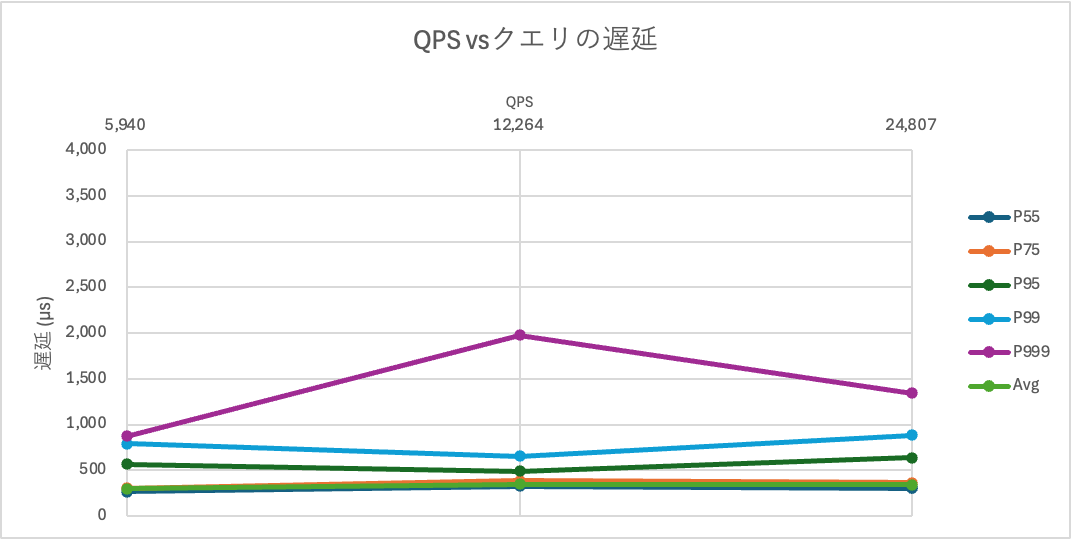

当初予定していた1200テナント想定の負荷である24000QPSも余裕で達成できました。またデータディクショナリへのアクセス待機時間は目立たなくなり、CPU待機時間が支配的な、健全なものであることが確認できます。
スキーマ数(=メタデータのサイズ)を固定すれば、より大きな負荷を捌けるはずという仮説は正しそうです。
結果まとめ
以上のことから、弊社のケースだと600テナント程度の収容が限界点であることが確認でき、負荷試験の目的を達成できました。また、MySQL8.0以降のスキーマ分離のデータ構造は、スキーマ数(テナント)の増加が性能のボトルネックになるという定性的な事実を数値的に理解することができました。
例えば、スキーマ数が数百程度までしか増加しない、スキーマあたりのテーブル数が多くない、などの場合は、「スキーマ分離・行分離の特性比較」の表で示したメリットを享受するために、スキーマ分離のデータ構造を選択するのもありなのかもしれません。しかし、スキーマ数が大きくスケールすることが予想されるサービスでは、行分離のデータ構造を採用することが無難と言えるでしょう。
なんとか延命したい
とはいえ、スキーマ分離で作ってしまったものを行分離に作り直すのはかなり骨が折れる作業になります。弊社でも長期的にはリアーキテクトが必要という認識にはなりましたが、中期的な事業計画・工数の観点から、なんとか延命措置を図れないかという議論が生まれました。
そこで、今回の試験結果をAWSのソリューションアーキテクト(SA)の方に共有をしたところ、以下のようなアドバイスを頂けました!
- table_open_cache, table_definition_cache の調整: オープンテーブルキャッシュのサイズを増やすことで、データディクショナリの参照頻度および競合発生頻度を抑えられるかもしれない
- innodb_sync_array_size の調整: 待機中のスレッドの数が多いワークロードの同時実行性が高まるので、競合の待機時間が短くなるかもしれない
- インスタンスタイプやストレージタイプの変更: r6g → r7g,r8gにすること、ストレージ設定をAurora I/O-Optimized に変更することなどで、パフォーマンスの向上が見込める
根本的な解決にはなりませんが、これらのチューニングを行うことで、現在よりもアーキテクチャ移行のデッドラインが後ろにずれる可能性があります。これらの調整を行ってみて、どのような結果が得られたかについては、また次回報告させていただきます!
MNTSQ株式会社 SRE 西室
{kind=link}