


シンガポールに拠点を置くAI開発企業のMiniMaxが、最新AIモデルの「MiniMax M2」をオープンソース化すると発表しました。
MiniMax M2 & Agent: Ingenious in Simplicity – MiniMax News
https://www.minimax.io/news/minimax-m2

Alibaba-Backed MiniMax Unveils Open-Source LLM M2, Rivaling Claude at 8% Cost
https://www.webpronews.com/alibaba-backed-minimax-unveils-open-source-llm-m2-rivaling-claude-at-8-cost/
MiniMax-M2 Open-Sourced, Outsmarts Claude Opus 4.1 in New AI Intelligence Index
https://analyticsindiamag.com/ai-news-updates/minimax-m2-open-sourced-outsmarts-claude-opus-4-1-in-new-ai-intelligence-index/
オープンソース化が発表されたMiniMax M2は、高度なコーディング能力と高いエージェント性能を併せ持ったAIモデルです。MiniMax M2はエンドツーエンドの開発者ワークフロー向けに設計されており、Claude Code、Cursor、Cline、Kilo Code、Droidといったコーディング向けAIと同等の強力なコーディング性能を有しています。また、mcp、シェル、ブラウザ、情報検索、Pythonコードインタープリターなどの長期的なツールチェーン操作を安定して処理することが可能です。
We’re open-sourcing MiniMax M2 — Agent & Code Native, at 8% Claude Sonnet price, ~2x faster
⚡ Global FREE for a limited time via MiniMax Agent & API
– Advanced Coding Capability: Engineered for end-to-end developer workflows. Strong capability on a wide-range of applications… pic.twitter.com/FoiAz9NF4q— MiniMax (official) (@MiniMax__AI) October 27, 2025
MiniMaxは「エージェントに対する私たちのニーズを完全に満たすAIモデルはひとつも存在しませんでした。課題は、パフォーマンス、価格、推論速度の適切なバランスを実現するAIモデルを見つけることでした。これはほぼ『不可能な三角形』です。海外の優れたAIモデルは優れたパフォーマンスを提供しますが、非常に高価であり、動作も比較的遅いです。中国産モデルは安価ですが、パフォーマンスと速度に差があります。そのため、既存のエージェント製品が優れた結果を得るには高価であったり、遅い場合が多くあります。例えば、多くのエージェントのサブスクリプションは月額数十ドル(数千円)、場合によっては数百ドル(数万円)もかかり、ひとつのタスクを完了するのに数時間かかることもあります」と言及しています。
そのため、MiniMaxはパフォーマンス、価格、推論速度のバランスをより良く実現するAIモデルの開発を模索してきました。そして誕生したのが、MiniMax M2というわけです。
エージェントにとって最も重要な3つの能力である「プログラミング」「ツールの使用」「ディープサーチ」のパフォーマンスを競合AIと比較した結果が以下のグラフです。比較対象となったのはDeepSeek-V3.2、GLM-4.6、Kimi K2 0905、Gemini 2.5 Pro、Claude Sonnet 4.5、GPT-5(thinking)の6つ。MiniMax M2は各種ベンチマークにおいて安定して高いパフォーマンスを発揮しています。
MiniMaxは「ツールの使用」および「ディープサーチ」の分野について、「MiniMax M2は海外の最先端AIモデルに非常に近いパフォーマンスを発揮することに成功しています。プログラミング能力では海外の最先端モデルにわずかに遅れを取っていますが、国内市場では既にトップクラスの性能です」と評しています。
ビジネスチームやバックエンドチームを含む開発者は、アルゴリズムエンジニアと協力し、環境構築と評価に多大な労力を費やし、日々の業務にAIをますます統合しています。これらの複雑なシナリオを習得した後、蓄積した手法を知識や数学といった従来の大規模モデルタスクに適用することで、自然に優れた結果を達成できることを発見したとMiniMaxは説明しました。
例えば、10のテストタスクを統合したArtificial AnalysisのIntelligenceベンチマークにおいて、MiniMax M2は世界でトップ5のパフォーマンスを発揮することに成功しています。
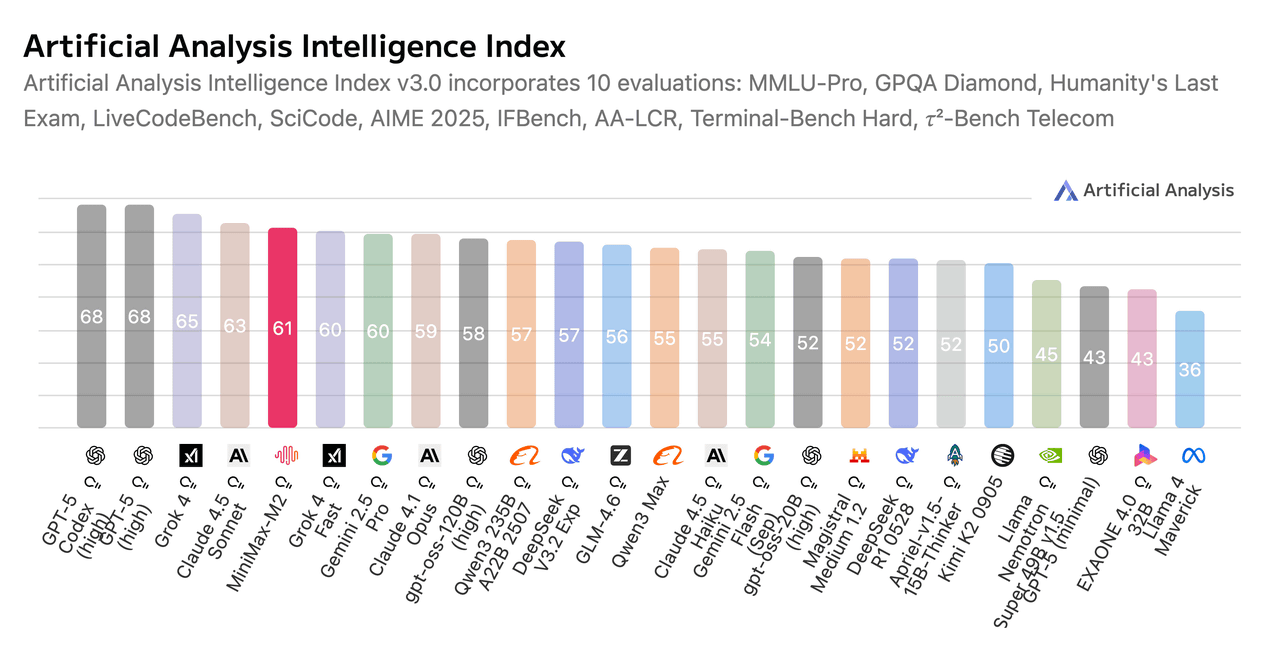
また、MiniMax M2のAPI価格は入力トークン100万個当たり0.3ドル(約46円)、出力トークン100万個当たり1.2ドル(約183円)です。この価格はClaude 3.5 Sonnetの約8%であるにもかかわらず、推論速度はMiniMax M2の方が2倍も高速となっています。
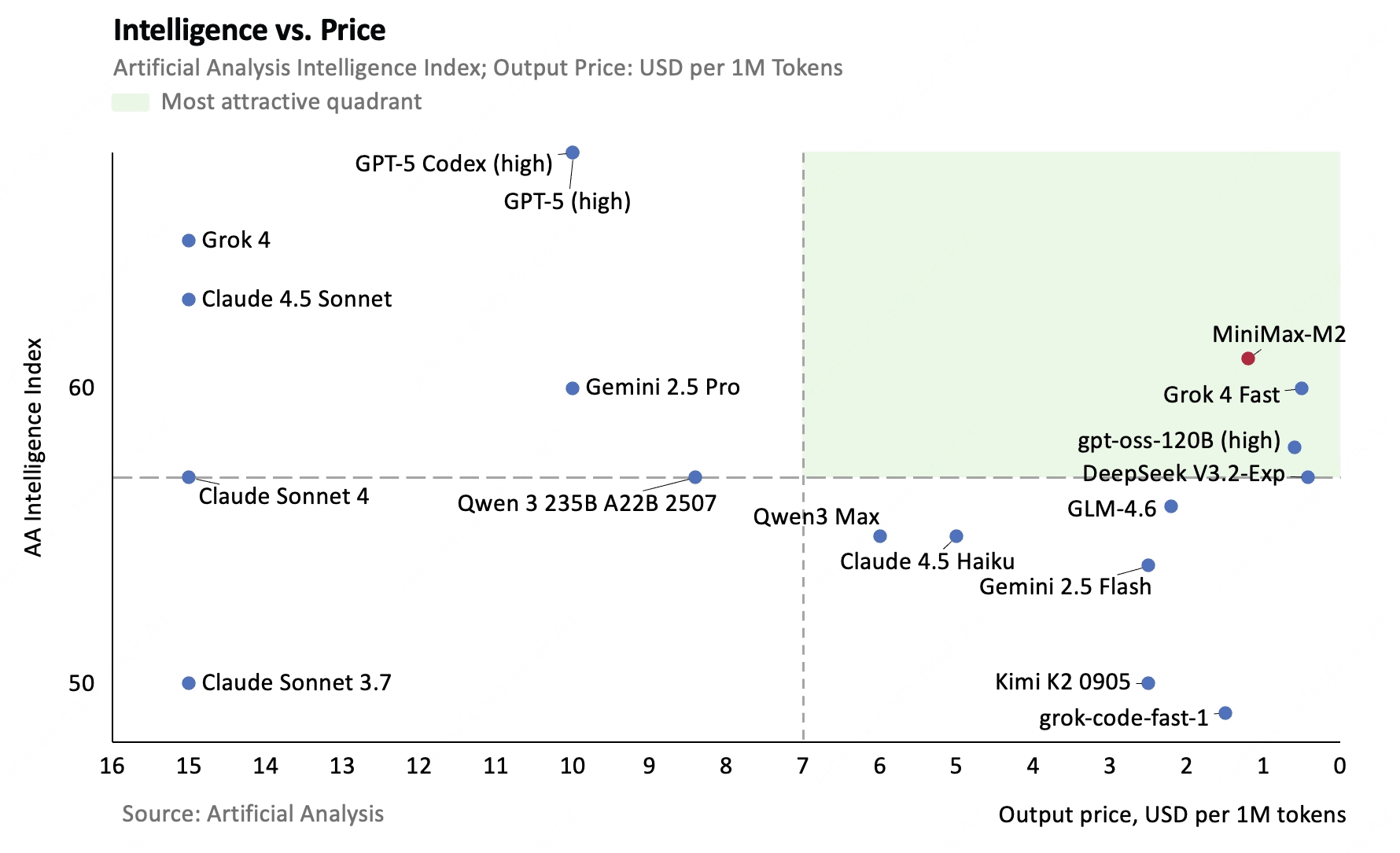
以下のグラフは各AIモデルの性能と価格を比較したものです。縦軸が性能(上にあるほど高性能)、横軸が価格(右に行くほど低価格)を表しており、MiniMax M2が性能と価格のバランスが取れたAIモデルであることがよく分かります。
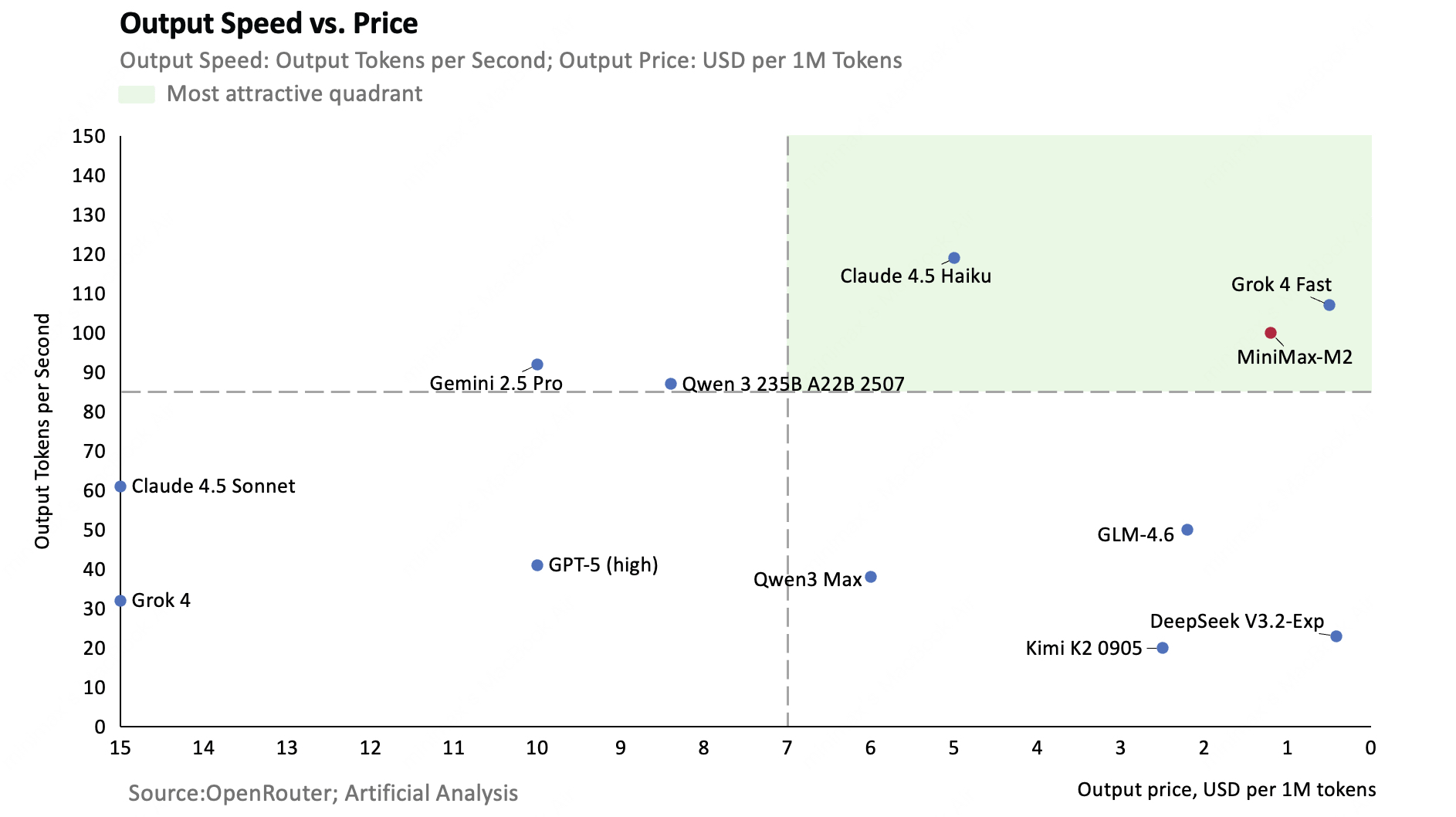
以下のグラフは各AIモデルの推論速度(縦軸)と価格(横軸)を比較したもの。推論速度はトップクラスでありながら、価格もトップクラスに安いです。
さらに、MiniMaxはMiniMax M2のAPIをトライアル期間として、協定世界時2025年11月7日0時まで無料で提供します。
また、MiniMax M2はHugging Face上からも利用可能です。
MiniMaxAI/MiniMax-M2 · Hugging Face
https://huggingface.co/MiniMaxAI/MiniMax-M2
Simon Willison氏はMiniMax M2について、「MITライセンスのAIモデルで、自己申告のベンチマークによると、Claude Sonnet 4と同等の性能を示しています。ただし、Claude Sonnet 4.5には及びません。Hugging Face上での配布サイズは230GBです。そのため、NVIDIA Sparkの128GBにはおそらく収まりませんが、Mac Studioの512GBでは動作するはずです」と解説しました。
MIT licensed model, their self-reported benchmarks show it performing similar to Claude Sonnet 4 (but still behind 4.5), and it’s only 230GB on Hugging Face
So likely won’t fit on an NVIDIA Spark’s 128GB but should run on a Mac Studio 512GB https://t.co/jzJ0GiDXj5
— Simon Willison (@simonw) October 27, 2025
Yifan Zhang氏は「1:MinimaxはGPT-OSSのような構造を使用しています。つまり、フルアテンションとスライディングウィンドウアテンション(SWA)が交互に配置されています。2:QKノルムを使用しており、すべてのアテンションヘッドにはそれぞれ独自の学習可能なRMSノルムがあります。3:フルアテンションとSWAの部分は設定を共有していません。それぞれ独自のRoPEシータ設定を持っています」と言及。また、リニアテンションを利用しない理由について、「フラッシュアテンション(Dao et al.)は非常に効果的で、低精度トレーニングと推論(FP8/FP4)をサポートしますが、リニアアテンションは低精度では機能しません!」と指摘しました。
💡Some fun facts about Minimax M2:
1. Minimax uses GPT-OSS-like structure, i.e., Full Attention interleaved with Sliding Window Attention (SWA).
2. It uses QK Norm, and every single attention head has its own unique, learnable RMSNorm.
3. The full attention and SWA parts… https://t.co/XBsvPFhBVt pic.twitter.com/CoSzljm3NB
— Yifan Zhang (@yifan_zhang_) October 27, 2025
MiniMax M2のモデルタイプが「mixtral」となっている点を指摘する声もあります。
M2 open sourced. That could be expected from them reporting the params upfront, but still I didn’t want to believe too early and get disappointed. Stellar ethics.
Except: model_type “mixtral”? What even is mixtral about it?
Some interesting research trajectory happened here… https://t.co/mZErdi5vSU pic.twitter.com/X7hIqS7eIN— Teortaxes▶️ (DeepSeek 推特🐋铁粉 2023 – ∞) (@teortaxesTex) October 27, 2025
さらに、MiniMax M2はvLLMでのDay-0サポートとともに提供されることも発表されています。これにより迅速かつ効率的な推論とスムーズな長文コンテキスト性能を実現するそうです。
🎉 Congrats to the @MiniMax__AI team for releasing MiniMax-M2 model!
Built for advanced coding and agentic tasks, MiniMax-M2 is now available with Day-0 support on vLLM, bringing fast, efficient inference and smooth long-context performance.
vLLM is proud to power the next… https://t.co/LZmvL2ZRTC— vLLM (@vllm_project) October 27, 2025
この記事のタイトルとURLをコピーする
{kind=link}