

はじめに
こんにちは。データサイエンティストの閔(みん)です。普段はAIレストラン検索アプリ「UMAME!」の開発に携わるほか、社内のデータ管理、AIを用いた業務改善などに関わっています。
本記事では、近年話題となっている LLM Agent (最近は単にAgentとも呼ばれます。以降Agentとします) の、会話内容をまとめて保持する「長期メモリ」の仕組みの一つであるMemory Bankについてご紹介したいと思います。その前に、Agentとは何かについても少しだけおさらいしたいと思います。
Agentって何?
Agentとは、一般的に 自ら環境を認識し、自律的に行動を行うAI と定義されるようです。(Agentについては、Google Cloud AI Agent Summitの登壇記事 に解説してありますのでご参考ください) 最近はGeminiやChatGPTにもAgent機能が追加されました。これは、あいまいな指示に対しても、自分で道筋を考え、使うツール (検索、画像生成など)を決めることができるようになった、という意味です。
Agentの主な構成要素として、「計画」「ツール」「メモリ(長期・短期)」が挙げられています。 これらの要素を組み合わせることで、AIは目標達成に向けた道筋を自ら立て(計画)、外部機能を利用し(ツール)、過去の情報を参照しながら(メモリ)、自主性・自立性を持たせることが可能となります。
Memory Bankについて
本記事では、Agentの構成要素の中でも、主に長期記憶に焦点を当てて解説をしていきたいと思います。ここで紹介したい仕組みは、Google社が開発したMemory Bankです。
Memory Bankは、2024年にAAAIで発表された長期メモリの仕組みです。この論文には、長期メモリの仕組みだけでなく、実際にこれを適用して作ったchatbotの例も紹介されています。
このMemory Bankは、次のようにしてメモリを保持します。
- 会話を要約し、重要な部分だけを抜き取る
- メモリの更新
- メモリの強度をアップデート: メモリが引き出された回数を「強度」と定義しています
- メモリの確率的忘却: 古いメモリは、エビングハウスの忘却曲線に沿って削除される
そして、メモリを引き出すときは、メモリ上でベクトル検索を行って関連するメモリを引っ張ってきます。この論文では、ベクトル検索を実現するために、FAISSというライブラリを使っています。
Memory Bankにおける会話の要約
Memory Bankは、会話をまとめて、大事な部分だけを残しています。論文の中では、次のようなプロンプトを使っています。
まず、会話全体を要約し、大事な出来事だけを残す時は次を使っています。
Summarize the events and key information in the content [dialog/events]*
そして、ユーザーの情報をまとめるときは次を使っています。
Based on the following dialogue, please summarize the user’s personality traits and emotions.[dialog]*
もしくは
The 3 following are the user’s exhibited personality traits and emotions throughout multiple days. Please provide a highly concise and general summary of the user’s personality[daily Personalities]*
ただし、これはあくまでも一例です。実際Memory Bankを使う時は、注目したい内容に合わせて要約のためのプロンプトを調整することもできます。
Memory Bankの更新
Memory Bankには、データがただただ蓄積されるわけではありません。メモリを入れるとき、その「強度」を1としてメモリが入ります。メモリが呼び出されたとき、その強度が1上がります。
その後、古いメモリを落とします。古いメモリは、次の確率で落とされます。
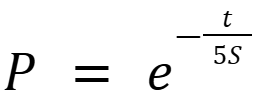
ここでtは経過日数で、Sはメモリの強度です。新しく入ったメモリは、経過日数が0日なので、絶対落とされませんが、ある程度日数が経っていて、かつあまり呼び出されていないものは確率的に落とされていきます。ここで分母に5をかけているのは、論文には記載がなく、githubのソースコードでのみ確認できる調整項です。これは、古いメモリが過度に削除されるのを防ぐための経験的な補正項であると推測されます。
Google ADK Memory Bankの話
Google Memory Bank for ADKとは
Google ADK (Agent Development Kit) は、2025年4月にリリースされた、LLM Agentを作るためのオープンソースライブラリです。Gemini APIとこちらのライブラリを使うことで、オリジナルのAgentを作ることができます。PythonとJavaでADKを使うことができますが、本記事ではPythonでの利用例のみ紹介します。
こちらのライブラリから、長期メモリの仕組みとしてMemory Bankを使うことができます。ここで、Memory Bankの使い方を解説していきたいと思います。ただし、こちらのサービスを使うには、次のような準備が必要です。
- Google Cloudの設定
- Google Cloudが使える状態にする
- 次のAPIを有効にする
- Gemini API
- Vertex AI
- Cloud Storage APIs
- ライブラリのダウンロード
- google-cloud-aiplatform
- google-adk
- google-genai
Google Memory Bankを使うための準備
Google Memory Bankを使うためには、まずReasoning Engineを作らないといけません。Reasoning Engineは、Google Cloud上にAgent用のコンテナを作ってくれるサービスです。Agent作成ライブラリの LangChain、 LangGraph、 AG2、 LlamaIndex、 ADKがサポート対象ですが、ADKは2025年9月現在まだPreviewとなっています。
この時、フォルダ構造は次のようにします。
my_sample_agent ├── deployment.py ├── env.json ├── my_sample_agent │ ├── __init__.py │ └── agent.py └── use_remote_agent.ipynb
次は、deployment.pyの一部です。
まず、次のように、Memory Bankの設定を入れて、Reasoning Engineを作成します。これらの設定は、後から修正できます。Memory Bankの設定項目については、こちらを参考にしてください。
import vertexai def create(): similarity_search_config = { "similarity_search_config": { "embedding_model": f"projects/{PROJECT_ID}/locations/{LOCATION}/publishers/google/models/gemini-embedding-001" } } context_spec = { "context_spec": { "memory_bank_config": { **similarity_search_config } } } app = AdkApp( agent=root_agent, enable_tracing=True, ) agent_engine = client.agent_engines.create( agent_engine=app, config={ "display_name": "my_sample_agent", "staging_bucket": bucket, "requirements": [ "google-cloud-aiplatform", "google-adk", "pydantic", "cloudpickle", ], "extra_packages": ["./my_sample_agent"], **context_spec } )
作成したReasoning Engineは、Google Cloud ConsoleのVertex AI > Agent Engineで確認することができます。

会話を覚えてくれるAgentを作る
次のように、ユーザーの会話を覚えてくれる簡単なAgentを作成します。Agentは、my_sample_agent/my_sample_agent/agent.py に作っておきます。
import asyncio from google.adk.agents import Agent from google.adk.tools.preload_memory_tool import PreloadMemoryTool root_agent = Agent( model="gemini-2.5-flash-lite", name="my_sample_agent", tools=[PreloadMemoryTool()] )
メモリを溜める
メモリを溜めるための準備
メモリのため方には2通りあります。1つは、Agentと直接会話をすることです。2つ目は、REST APIを使って直接注入することです。
ここで、Agentと会話をする方法が2つあります。
1つ目は、Google ADKのSessionクラスを使って会話のSessionを自分で作って、Google ADKのRunnerを使ってSessionを動かす方法です。2つ目は、Agentを先ほどのReasoning Engineへ登録してクエリを流す方法です。AgentをReasoning Engineに登録すると、自分でRunnerを作らなくて済むので、今回は2つ目の方法でAgentを動かしてみようと思います。
では、まずdeployment.pyに次のコードを追加し、Reasoning Engineをアップデートします。
from vertexai.preview.reasoning_engines import AdkApp from google.adk.memory.vertex_ai_memory_bank_service import VertexAiMemoryBankService from google.adk.sessions import VertexAiSessionService from my_sample_agent.agent import root_agent def update(): def memory_bank_service() -> VertexAiMemoryBankService: return VertexAiMemoryBankService( project=PROJECT_ID, location=LOCATION, agent_engine_id=reasoning_engine_resource_id, ) def session_service() -> VertexAiSessionService: return VertexAiSessionService( project=PROJECT_ID, location=LOCATION, agent_engine_id=reasoning_engine_resource_id, ) app = AdkApp( agent=root_agent, enable_tracing=True, session_service_builder=session_service, memory_service_builder=memory_bank_service, ) agent_engine = client.agent_engines.update( name=reasoning_engine_resource_name, agent_engine=app, config={ "staging_bucket": bucket, "requirements": [ "google-cloud-aiplatform", "google-adk", "pydantic", "cloudpickle", ], "extra_packages": ["./my_sample_agent"], , **context_spec } )
メモリを溜める例1: 会話の終了時にAgentとのやり取りをまとめる
まず、作ったAgentと会話をしてみます。
import vertexai client = vertexai.Client( project=PROJECT_ID, location=LOCATION ) app = client.agent_engines.get(name=resource_name) USER_ID = "test_user" session = app.create_session(user_id=USER_ID) for event in app.stream_query( user_id=USER_ID, session_id=session["id"], message="私が一番好きな果物はぶどうです。その中でもシャインマスカットが一番好きです" ): print(event["content"]["parts"][0])
会話が終わったら、以下のようにして、セッションをまとめてメモリを作成することができます。
response = client.agent_engines.memories.generate(
name=resource_name,
vertex_session_source={
"session": f"{resource_name}/sessions/{session['id']}"
},
scope= {
"app_name": APP_NAME,
"user_id": USER_ID
}
)
メモリを溜める例2: 自分で注入する
メモリに直接内容を注入することもできます。この場合は、Agentと会話しなくても、メモリだけ入れることができます。
client.agent_engines.memories.generate(
name=resource_name,
direct_memories_source={"direct_memories": [{"fact": "私が最後に映画館に行ったのは2024年です"}]},
scope={
"app_name": APP_NAME,
"user_id": USER_ID
}
)
メモリを使う
メモリは、AgentのToolの中、もしくは外から検索・参照することができます。こちらでは、Agentの外から検索する例だけをお見せしたいと思います。ここでは、会話のとき入れた情報である「好きな果物」で検索をかけてみます。
list( client.agent_engines.memories.retrieve( name=resource_name, scope={ "app_name": APP_NAME, "user_id": USER_ID }, similarity_search_params={ "search_query": "私が一番好きな果物は?", "top_k": 1 } ) )
そうしたら次のような結果が返ってきました。
[RetrieveMemoriesResponseRetrievedMemory( distance=0.41006403295076066, memory=Memory( create_time=datetime.datetime(2025, 8, 27, 2, 21, 46, 373034, tzinfo=TzInfo(UTC)), fact='My favorite fruit is grapes, especially Shine Muscat grapes.', name='projects/{PROJECT_ID}/locations/{LOCATION}/reasoningEngines/{ENGINE_ID}/memories/{memory_id}', scope={ 'app_name': 'my_sample_agent', 'user_id': 'test_user' }, update_time=datetime.datetime(2025, 8, 27, 2, 51, 33, 411266, tzinfo=TzInfo(UTC)) ) )]
AgentのToolの中でも検索ができるようになっていますが、その仕組みの解説は、ここでは割愛させていただきます。
まとめ
本記事では、LLM Agentのためのlong-term memoryサービスとしてGoogle社が開発したMemory Bankについてご紹介しました。Memory Bankは、メモリの保存方式が直感的で、またフルマネージドサービスなので、容量を気にすることなく使えるサービスとなっています。ただ、Long-term memoryの管理方法は、他にもいくつかありますので、ユースケースや現在サービスしているプロダクトのアーキテクチャなどを考慮して選ぶと良いと思います。
*:参考文献: AAAI MemoryBank: Enhancing Large Language Models with Long-Term Memory
https://ojs.aaai.org/index.php/AAAI/article/view/29946
(2025/10/20アクセス)

{kind=link}