
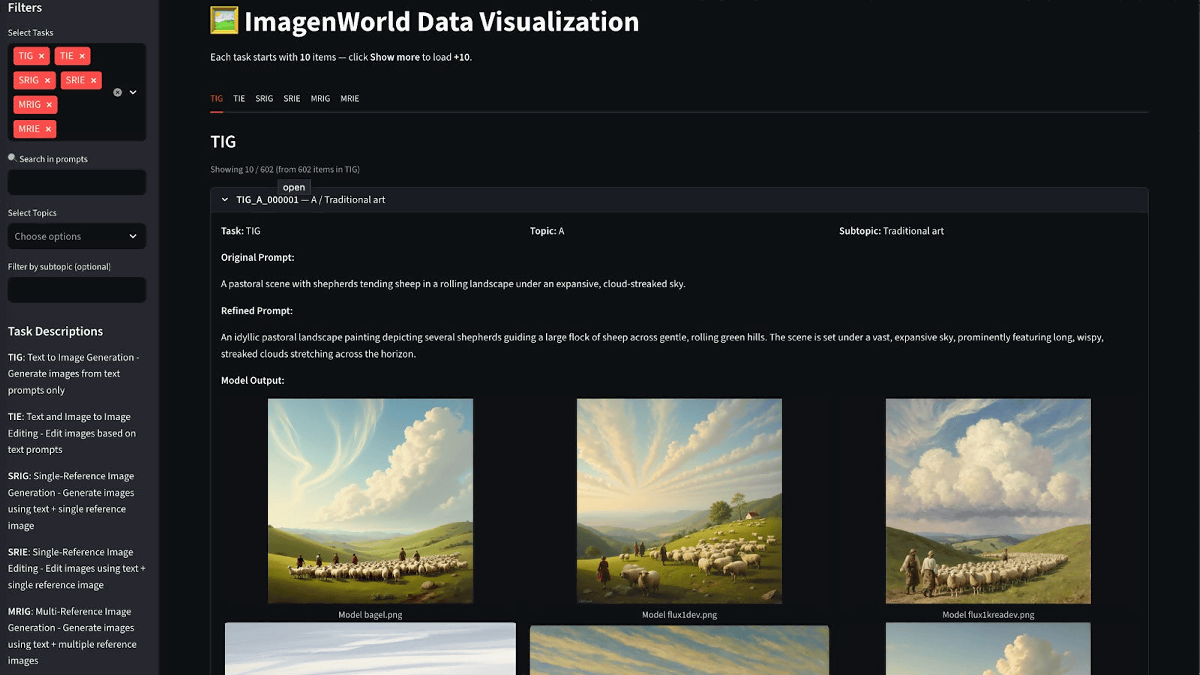
画像生成AIの性能は「他のAIと比べてキレイな画像を生成できる」といった数値化しにくい形式で評価されることが多いです。「ImagenWorld」はウォータールー大学やComfy.orgの研究チームが開発したベンチマークで、各種AIに画像生成や画像編集などのタスクを課して性能を定量的に評価することができます。
ImagenWorld: Stress-Testing Image Generation Models with Explainable Human Evaluation on Open-ended Real-World Tasks
https://tiger-ai-lab.github.io/ImagenWorld/
Introducing ImagenWorld: A Real World Benchmark for Image Generation and Editing
https://blog.comfy.org/p/introducing-imagenworld
ImagenWorldは「テキストで指示して画像生成(TIG)」「テキストで指示して画像編集(TIE)」「単一の画像とテキストで指示して画像生成(SRIG)」「単一の画像とテキストで指示して画像編集(SRIE)」「複数の画像とテキストで指示して画像生成(MRIG)」「複数の画像とテキストで指示して画像編集(MRIE)」という6種類の課題を画像生成AIに与えて、AIが課題を達成できるか否かをテストします。AIの生成結果は「プロンプトの指示に従っているか」「視覚的に一貫性があるか」「すべての要素が論理的な意味を成しているか」「生成画像に含まれる文字列が判読不能でないか」といった基準で評価されます。
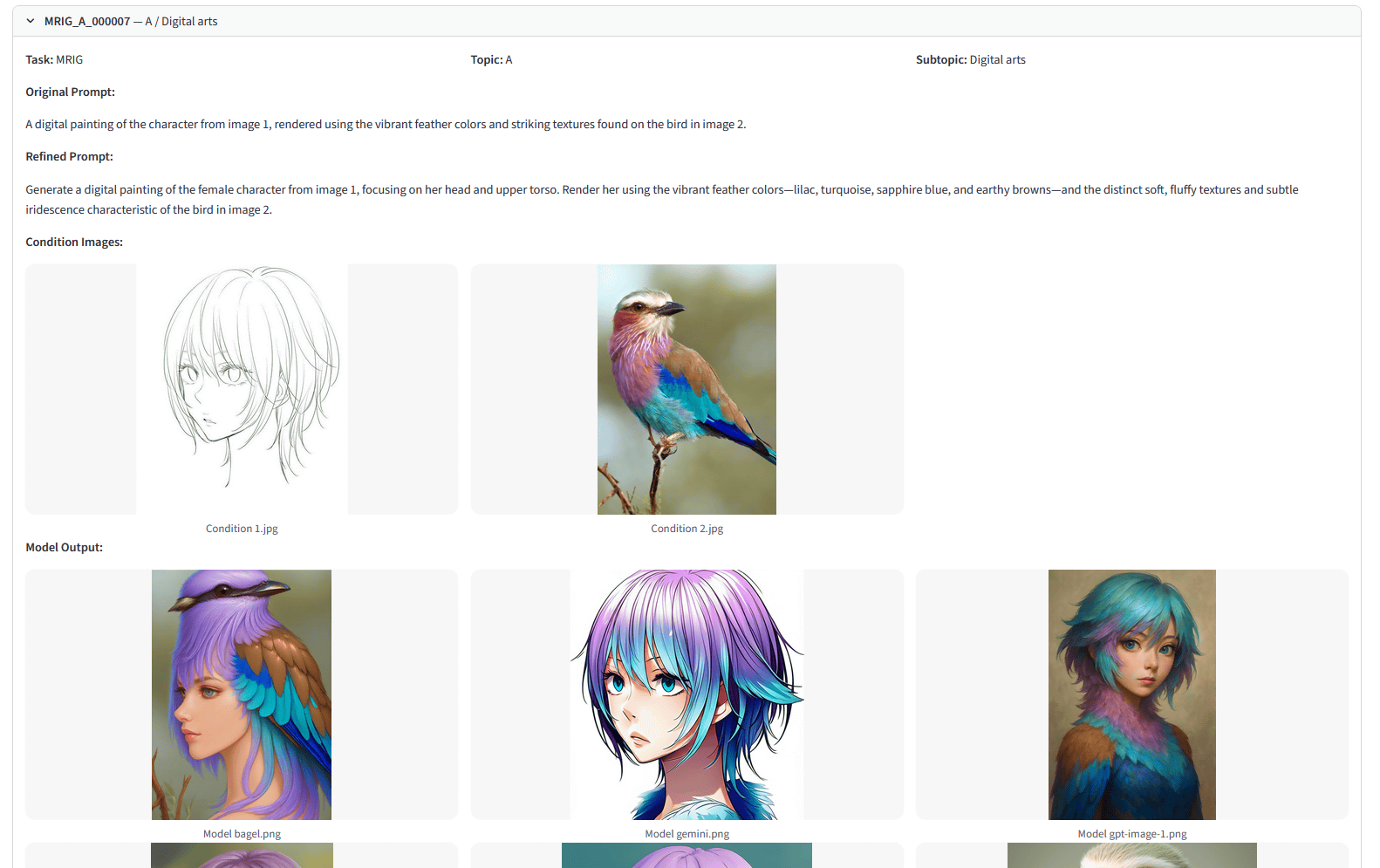
ImagenWorldのテスト内容とテスト結果は「ImagenWorld Visualizer」というページにまとまっています。例えば以下のテストは「女性を描いた『画像1』を『画像2』に写る鳥の色やテクスチャを用いて着色する」という指示を与えるものです。結果を見ると、Gemini 2.0 Flash(下段中央)は指示通りの結果を出力できていますが、BAGEL(下段左)とGPT-Image-1(下段右)は指示とかけ離れた画像を出力していることが分かります。
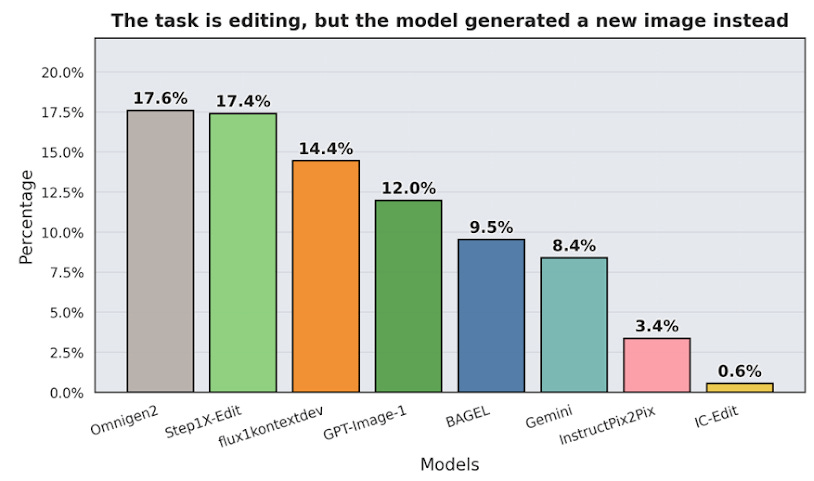
研究チームはすでに複数の画像生成AIを対象にImagenWorldのテストを実施し、得られた知見を公開しています。以下のグラフは「画像を編集するタスクを与えた際に、元の画像を無視してまったく新しい画像を生成してしまった割合」を示したもので、Gemini 2.0 Flashのような最先端モデルでも8.4%の割合で指示を無視してしまったことが分かります。
また、多くのAIが「『画像A』の指示通りの位置に、『画像B』と『画像C』に含まれる要素を追加する」というタスクを苦手としていました。

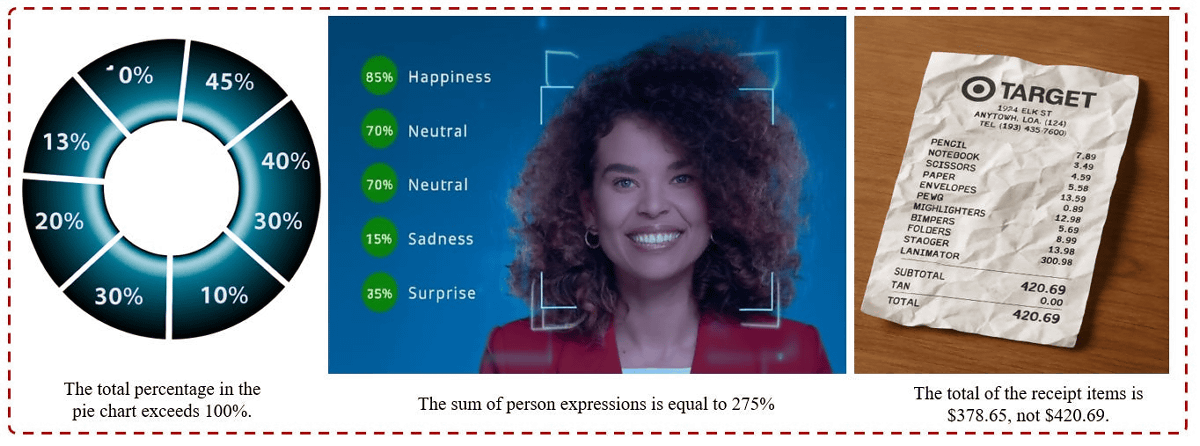
「割合を示すグラフ」を生成する際に合計値が100%を超えてしまうことが多いほか、レシートを生成する際に合計価格を間違えて記載してしまうこともあります。
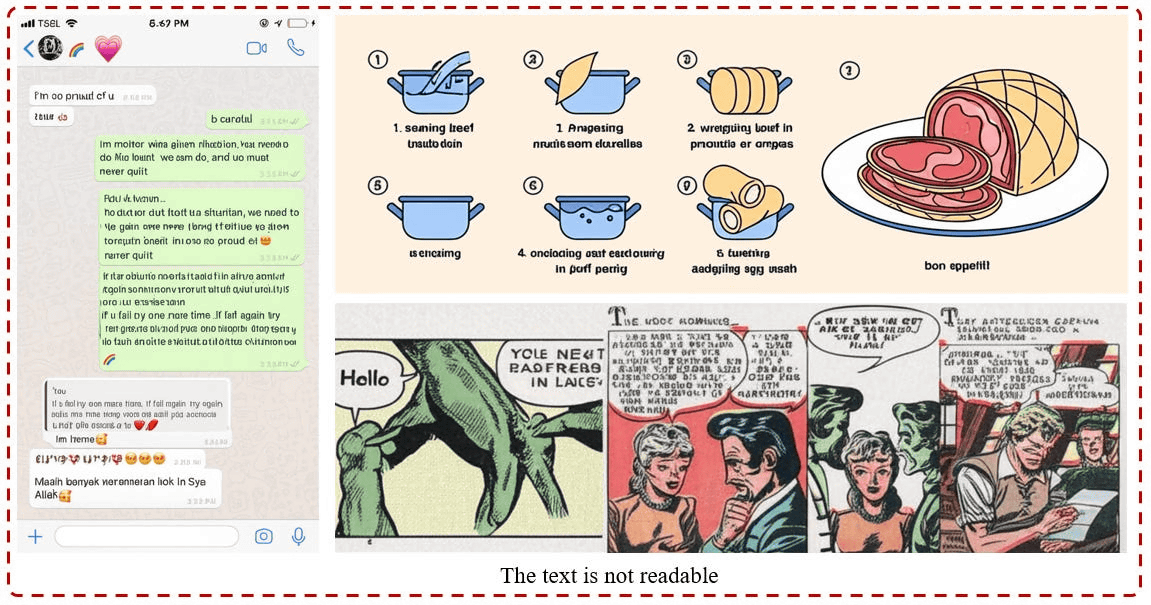
文章や説明イラストの生成もほとんどのAIにとって困難な課題です。
研究チームはImagenWorldを「次世代の画像生成AIモデルを評価するためのフレームワーク」として位置付けており、ImagenWorldでの評価を活用することで堅固かつ信頼性の高い生成システムを構築できるようになると述べています。
なお、ImagenWorldに含まれる指示内容や参考画像は以下のリンク先で公開されています。
TIGER-Lab/ImagenWorld · Datasets at Hugging Face
https://huggingface.co/datasets/TIGER-Lab/ImagenWorld
この記事のタイトルとURLをコピーする
元の記事を確認する
{kind=link}