

すべてのWebページをAPI化したい @ypresto (プレスト) です。
この記事はLayerX AI Agentブログリレー、28日目の記事です。
前回のわたしの記事では、身近なAgentの例として、Geminiのアプリを挙げました。Googleは様々なデータやAPIを通して「世界を整理している」ことは、Agent開発に大きなアドバンテージがあることは想像に難くありません。
一方でAgentで処理したい情報、自動化したい作業は、認証画面の向こう側にあるWebアプリであることも少なくないはずです。例えば前回の記事で「学童保育の出欠申請フォーム」を挙げました。
あらゆる認証ありのウェブサイトをAPI化・MCP化できない限り、Agentによるブラウザ操作の検討は避けては通れない道です。
そこで今回は、Playwright MCPやChrome DevTools MCPのセットアップが困難な、「不特定の一般ユーザー」を対象として、Agentに「ユーザー認証情報付きでブラウザの操作」を行わせる方法をいくつか検討してみたいと思います。
実現方法の検討
体験と安全性の観点で、次の点について考慮する必要があります。
-
インストール方法
学童保育のエージェントの例がわかりやすいですが、一般ユーザー向けではユーザーにとっていかに簡単にセットアップ・運用できるかが大切です。Playwright MCPを運用していただくのはハードルが高いと感じます。
-
セキュリティとセッション管理
ユーザー側のブラウザ操作を行う際に避けられない、認証情報の管理方法に気をつける必要があります。例えばAgentにパスワードを入力してブラウザでログインさせる方法も可能ですが、ユーザーの機密情報をサーバに転送することのリスクは極力避けたいです。
ブックマークレット
最も単純な方法は、ブックマークレットを使って操作対象のウェブページに、直接スクリプトを追加する方法です。実装も利用も簡便ですが、ページ遷移のためにリセットされてしまうため、常用するには難しいと思います。
下記のrepositoryで、実際にブックマークレット経由で閲覧中のウェブページの情報を引き抜くPoCを試すことができます。
https://github.com/ypresto/bookmarklet-agent-poc
ブラウザ拡張
Chrome拡張から操作する方法です。権限さえ付与されていれば、任意のウェブサイトを操作できるという簡便さがあります。
セキュリティの都合でContent ScriptsやService Worker等といった部品に分かれており、それぞれの通信を postMessage() で実装する必要があります。
任意のウェブサイトにアクセス可能な拡張は、審査に時間がかかるというデメリットもあります。
インストール型アプリ
同梱されたブラウザを直接操作することをイメージしています。環境によってはインストールに許可が必要であったり、更新を管理して貰う必要があるなど、個人で扱っていただくには少々骨が折れると感じます。
サーバサイドブラウザ
サーバ側でブラウザを実行するものの例として、CloudflareのBrowser Renderingがあります。またCloudflareのWorkerとして、Browser Renderingを使うPlaywright MCPをすぐ起動でき、下記のページからworkerの公開URLを指定することですぐに試せます。
https://playground.ai.cloudflare.com/
※ ただし上記のPlaywright MCPはデフォルトで公開URLになっているので、 wrangler.toml に workers_dev = false を使用し、Service bindings 経由で使用することで、セキュリティを確保してください。
対象ページがログイン不要であれば大変役立つかと思われます。
比較表
まとめると下記のようになります。
| 方法 | セットアップ | 使用時のUX | セキュリティ | プラットフォーム | 実装上の課題 |
|---|---|---|---|---|---|
| ブックマークレット | ⚠️ スクリプトのコピー&ペーストが必要 | ❌ ページ遷移ごとにクリックで起動必要 | ⚠️ 生スクリプトを扱わせる危険性 | ⚠️ 環境によって制限あり | なし |
| ブラウザ拡張 | ✅ 拡張ストアからインストール、更新も容易 | ✅ 自動で起動 | ⚠️ 権限管理に注意が必要 | ❌ PCブラウザのみ | ブラウザ拡張のセキュリティモデルへの対応 |
| インストール型アプリ | ❌ バイナリ配布とインストール | ✅ 自動で起動 | ✅ 隔離環境 | ⚠️ ビルド必要 | アプリの新規開発 |
| サーバサイドブラウザ | ✅ 配布不要 | ⚠️ サーバ側の状態を可視化する必要あり | ❌ 対象ページのセッション情報をサーバ側で扱う | ✅ 問わない | デバッグの不便さ |
ブラウザ拡張の実装への挑戦
検討した結果、ブラウザ拡張での操作が実現できると様々な応用が効く可能性が高いと考え、実装を始めてみています。下記のようにブラウザ内のチャットから他のタブを開き、そのタブを操作できるものになる予定です。
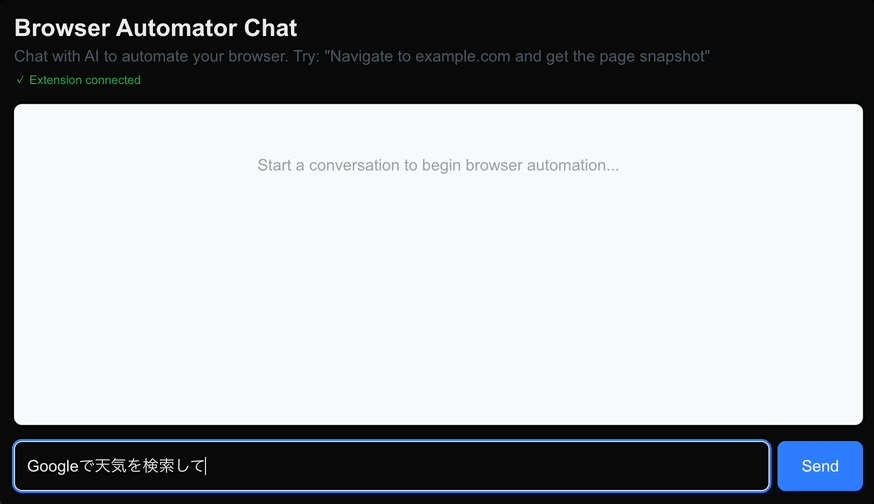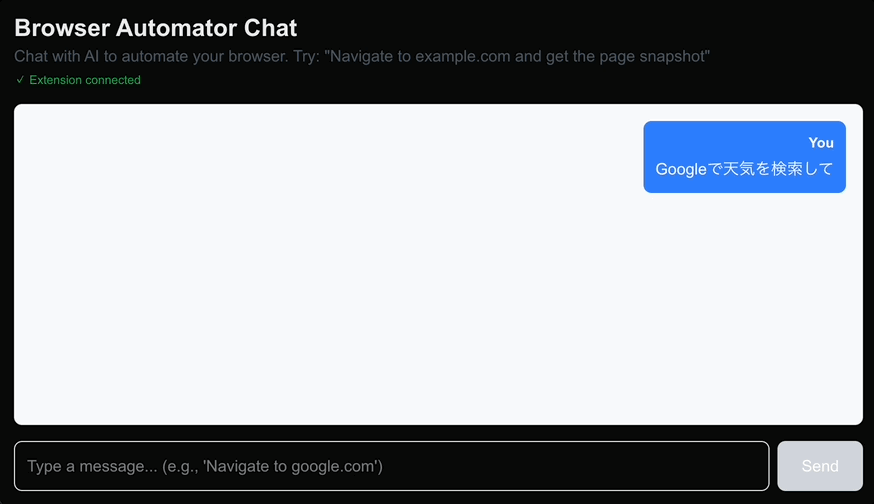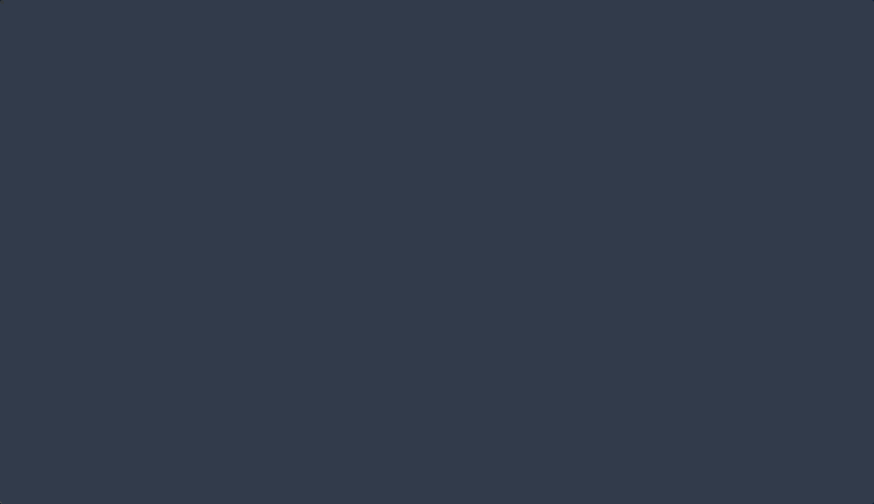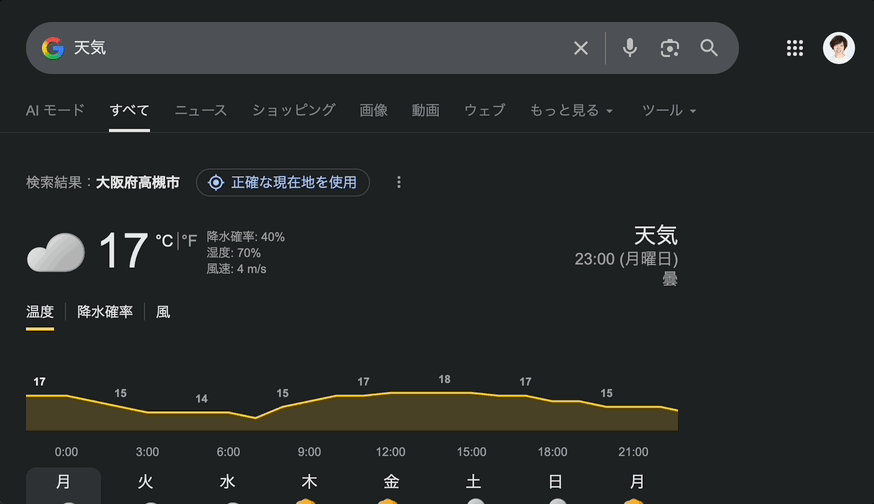
vercel/ai-sdkに対してtoolsを渡すだけで
import { createBrowserTools } from '@browser-automator/ai-sdk'; import { createControllerSDK } from '@browser-automator/controller'; function ...() { ... const adapter = createAdapter(); const sdk = createControllerSDK({ adapter }); await sdk.connect('demo-token'); const tools = createBrowserTools(sdk); const modelMessages = convertToModelMessages(messages); const result = streamText({ model: openai('gpt-4o-mini'), system: 'You are an AI assistant that helps users by performing tasks in a web browser using browser automation tools when needed.', messages: modelMessages, tools, stopWhen: stepCountIs(20), }); ... }
こちらは未完成ですが、鋭意以下のrepositoryで開発していく予定ですので、ご期待くださいませ。
(構成図も貼りますが、Chrome拡張はセキュリティ対策のための分離が強く、タブ間のコミュニケーションに少々無理が出てしまっています。)
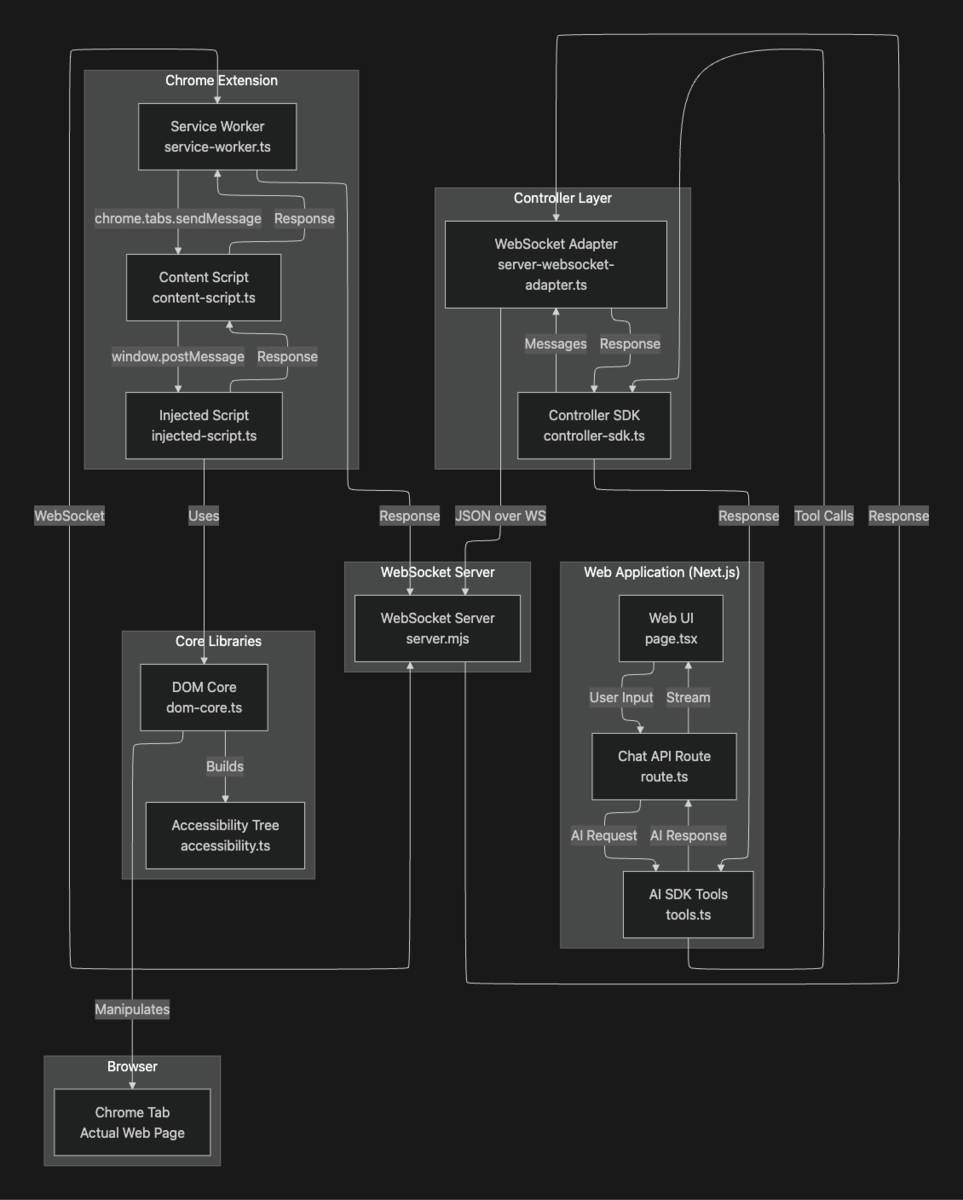
将来的にClaude For Chromeが全ユーザーに利用可能になれば、ユーザー自身がある程度の操作を組み立てることができるかもしれません。こちらは現在はResearch Previewとのことでした。
Agentとブラウザの関係、今後の展開を楽しみですね・・! わたしも面白いものを作っていければと思います。
{kind=link}